
使用python爬虫爬取链家潍坊市二手房项目

1、需求分析
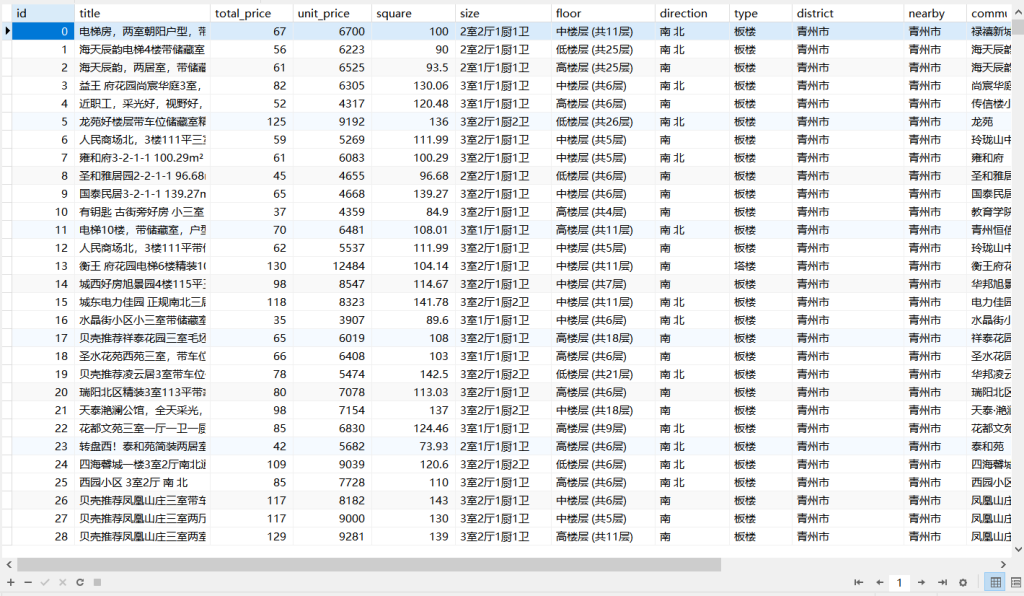
需要将潍坊市各县市区页面所展示的二手房信息按要求爬取下来,同时保存到本地。
2、流程设计
- 明确目标网站URL( https://wf.lianjia.com/ )
- 确定爬取二手房哪些具体信息(字段名)
- python爬虫关键实现:requests库和lxml库
- 将爬取的数据存储到CSV或数据库中
3、实现过程
3.1 项目目录
程序目录文件夹名为**secondhouse_spider,内有lianjia_house.py和Spider_wf.py**两个python文件

3.2 具体实现
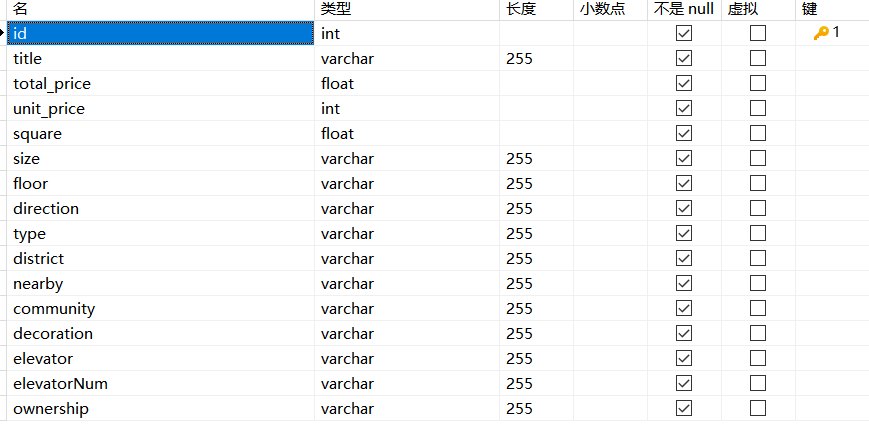
3.2.1 在数据库中创建数据表
我电脑上使用的是MySQL8.0,图形化工具用的是Navicat.
数据库字段对应
- id-编号
- title-标题
- total_price-房屋总价
- unit_price-房屋单价
- square-面积
- size-户型
- floor-楼层
- direction-朝向
- type-楼型
- district-地区
- nearby-附近区域
- community-小区
- elevator-电梯有无
- elevatorNum-梯户比例
- ownership-房屋性质
下图显示的是数据库字段名、数据类型、长度等信息。
3.2.2自定义数据存储函数
这部分代码放到**Spider_wf.py文件中
通过write_csv函数将数据存入CSV文件,通过write_db函数将数据存入数据库**
1 | import csv |
3.2.3 爬虫程序实现
这部分代码放到lianjia_house.py文件,调用项目Spider_wf.py文件中的write_csv和write_db函数
1 | #爬取链家二手房详情页信息 |
3.2.4 效果展示
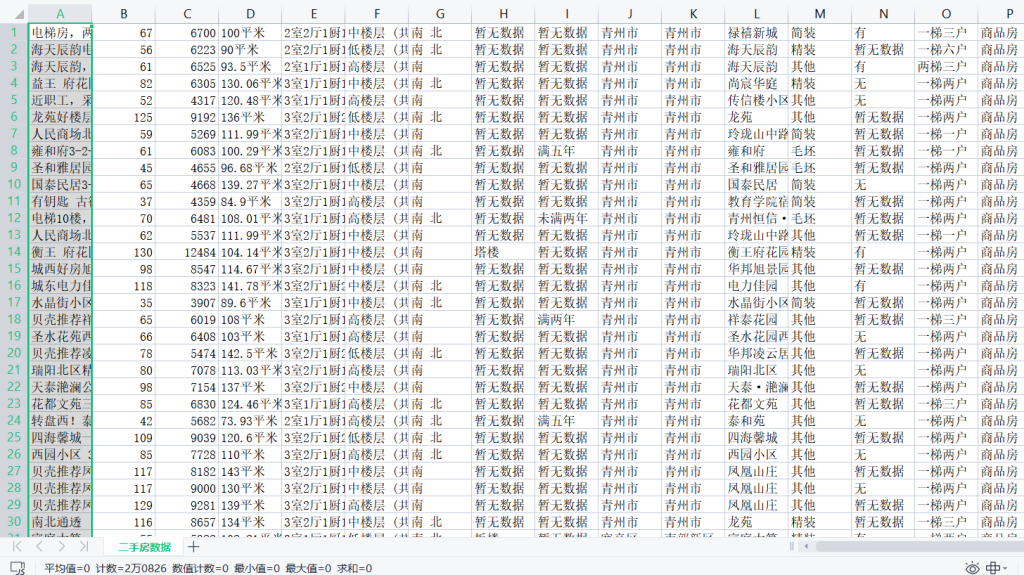
总共获取到20826条数据
我数据库因为要做数据分析,因而作了预处理,获得18031条
4、总结
最后,以上就是我使用python的requests库与lxml库爬取潍坊链家二手房项目的具体实现过程,有疑问的地方欢迎交流!
- 标题: 使用python爬虫爬取链家潍坊市二手房项目
- 作者: 狮子阿儒
- 创建于 : 2023-04-06 15:15:33
- 更新于 : 2024-03-03 21:30:30
- 链接: https://c200108.github.io/blog/2023/04/06/使用python爬虫爬取链家潍坊市二手房项目/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。
评论