
数据挖掘学习记录(一):科学计算库numpy

科学计算库Numpy
在python数据科学领域,包括数据分析、数据可视化、机器学习等等方面,Numpy是用得最广泛的工具包之一,基本涉及到数据计算、转换、清洗等等任务都能看到他的影子。
在机器学习、深度学习中,常常用到矩阵计算,而包含多个特征的数据往往都可以转换为矩阵:行是每一条样本数据,列就是其每个字段的特征。相较于传统的循环列表相乘,Numpy在矩阵计算上非常高效,可以节省大量运行时间,接下来学习Numpy的核心模块与常用函数用法
基本操作
Anaconda往往都默认安装了Numpy,如果用的是pip,就pip install numpy安装一下,安装完后,导入到运行环境中,为了方便,不要忘了给numpy起一个别名 import numpy as np
array数组
我们知道Python中有四种基本数据类型,如列表List、元组Tuple、集合Set和字典Dictionary,而numpy也有自己独特的数据类型,为ndarray(多维数组),是Python进行科学计算时基本的数据类型
如何创建?
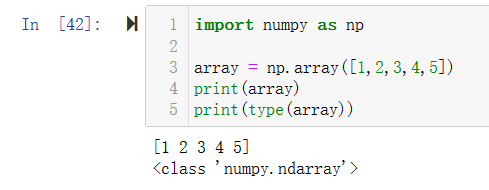
如下图,先导入numpy库,方法**np.array(参数)**用来创建array数组,其中参数为一维列表或多维列表。
数组间可以直接相加,相减,相乘,相除:

但是注意,运算的两个数组应该保持相同元素数,如下图,3个元素与五个元素相加出现错误,乘除如此:

使用ndarray数组时,数组中的所有元素必须是同一类型的,如果不是同一类型,数组元素会自动地向下进行转换,int–float–str,示例如下:

属性操作
type方法
用**type()**可以看到array类型为ndarray数据类型。
dtype方法
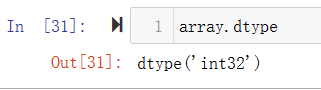
array.dtype 打印当前数据格式,查询当前数据元素的类型
shape方法
array.shape表示数组的维数,如下图:

array4数组是一个三维数组
- **shape[0]**表示第一维,shape[0]=2表示元素有两个
- **shape[1]**表示第二维,shape[1]=4表示元素有四个
- **shape[2]**表示第三维,shape[2]=1表示元素有1个
数字不断增大,维数由外到内。
size方法
array.size 打印当前数组中的元素个数

ndim方法
array.ndim 打印当前数据维度

索引与切片
数值索引
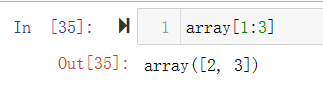
对array([1,2,3,4,5])执行索引与切片操作
[1:3]表示左闭右开,索引从0开始,即第一、二共两个元素
[-2:] 负数为从倒数开始读数据,表示从倒数第二个元素开始取,直到最后。

可以对索引位置进行赋值操作
当数组是多维时,索引操作如下:
- 取第二行数据

- 取第二列数据

bool索引
创建方法:np.array([1,0,1,···], dtype=bool)
常常搭配数组,用于放回对应True的元素,示例如下:
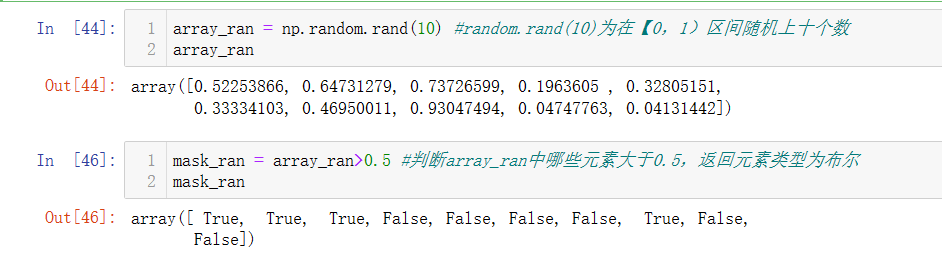
- 先用np.arange(起始, 终末, 步长)创建一个0-100以10为间隔的数组[0,10,20,30,40,50,60,70,80,90],然后创建bool数组,数组名[bool数组名] 获得True对应的数组!(注意:task_array与mask的元素数应该一致)

- 可以判断数组中的每个元素是否满足要求,返回布尔类型。
- 还可以将索引判断条件置于数组中,查找满足条件的具体元素值
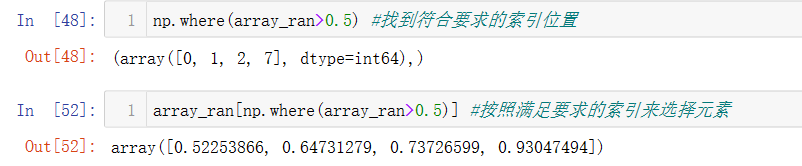
- 可以用于对比两个数组,或者快速进行逻辑判断操作。

数据类型与数值计算
数据类型
- 为了满足不同需要,可以在创建数组时指定其数据类型:
float16:半精度;float32:单精度;float64:双精度。如果没有较高精度要求,半精度能够大幅节省计算成本与时间,对于深度学习大规模参数计算,能降低数据传输与存储成本,加快训练速度。

- 数组数据类型转换,利用np.asarray(原始数组, dtype =目标类型) 即可得到目标数据类型数组,如下为int型转换为float32类型:

复制与赋值
- 如果想将一个数组的元素赋给另一个数组,可以用如下方法:
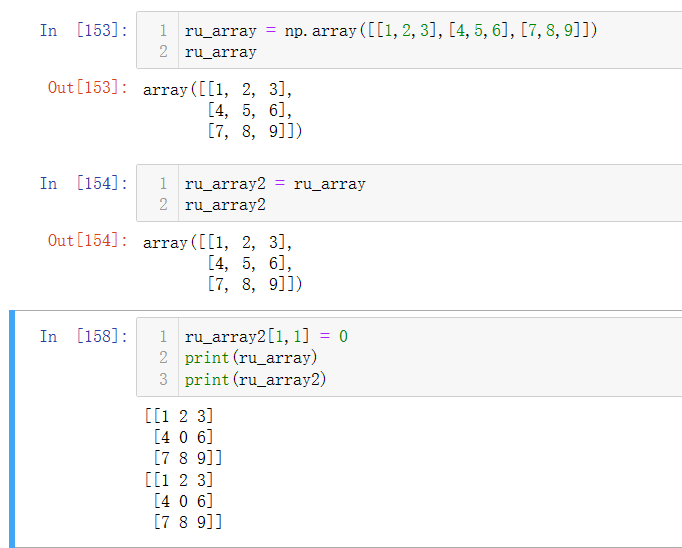
但是,可以看到,当ru_array2中的元素改变时,原有数组ru_array中元素也发生了改变,因而,这种赋值方法实际上不过是用两个名称表示了同一个数组罢了。
- 如果想让新数组的元素与之前的数组元素没有关联,该怎么办呢?
利用copy()方法,这样ru_array2与ru_array根本就是两回事了。

- 在numpy中有许多数值计算的操作,下面是常用的一些:
np.sum(array)
求和,参数axis = 为0表示列,为1表示行。

array.prod()
表示数组中各元素累乘,同时参数axis是针对列的乘积与各单位数组的乘积:

array.min()、array.max()、array.mean()
分别为求数组中元素最小值、最大值以及平均值。

array.std()、array.var()
分别表示求数组元素的标准差与方差。

a.clip(a_min, a_max)
其中a是一个数组,后面两个参数分别表示最小和最大值,clip这个函数将将数组中的元素限制在a_min, a_max之间,大于a_max的就使得它等于 a_max,小于a_min的就使得它等于a_min。

array.round()
表示对数组元素小数部分进行四舍五入,参数decimals为指定精度,示例中decimals=1表示精确到一位小数:

矩阵乘法
这里介绍两种计算方法,一种是按对应位置元素进行相乘(1);另一种是在数组中进行矩阵乘法(2)
(1)np.multiply()方法
对元素各对应位置相乘,返回计算后的数组:
(2)np.dot()方法
为矩阵乘法,按照数学规则相乘: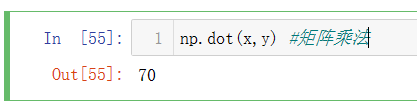
关于numpy.dot的具体介绍请见numpy官网:numpy.dot — NumPy v1.24 Manual
矩阵计算在线性代数中讲过,在numpy中也有矩阵运算的方法,矩阵与多维数组类似
如矩阵 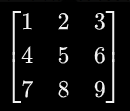 ,如果用数组可以表示为**array[[1,2,3],[4,5,6],[7,8,9]],每个括号的元素组成矩阵的行
,如果用数组可以表示为**array[[1,2,3],[4,5,6],[7,8,9]],每个括号的元素组成矩阵的行 1 2 3/4 5 6/7 8 9,每一行的相同索引位置组成矩阵的列1 4 7/2 5 8/3 6 9**,
上述(2)中所示为只有一行的矩阵相乘:dot(a, b)[i,j,k,m] = sum(a[i,j,:] * b[k,:,m]))
如果是多行矩阵相乘呢?
下面示例:
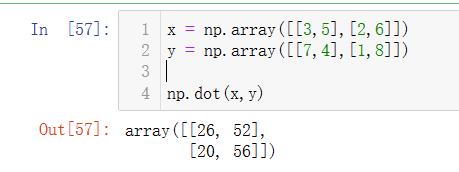
二维数组x与y进行矩阵计算,x = 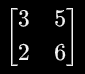 ,y=
,y=  ,矩阵计算过程为
,矩阵计算过程为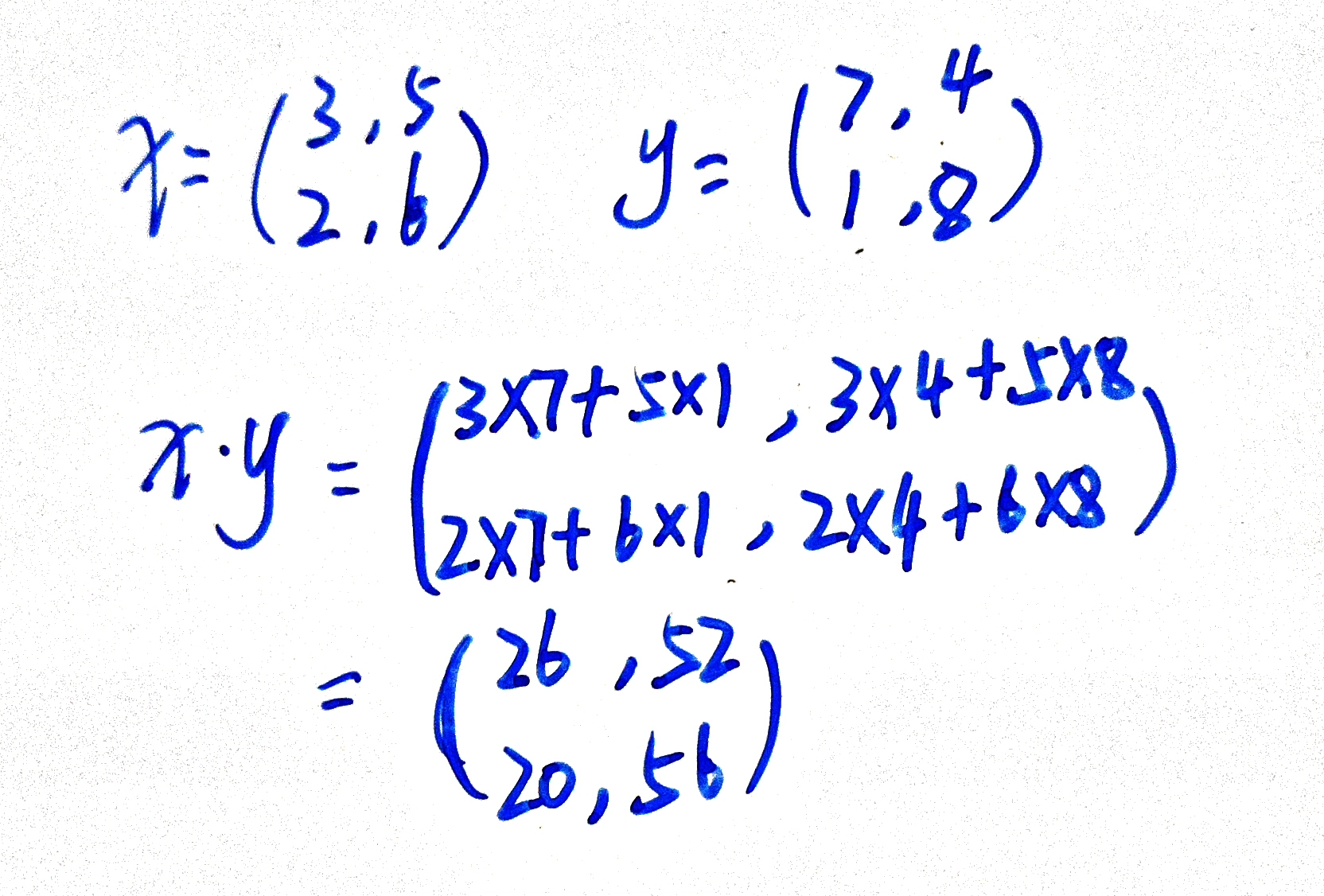
常用功能模块
排序操作
np.sort()
将数组按照升序排序,参数axis = 0表示列排序;axis=1表示行排序

np.argsort()方法
返回排序前元素的索引位置,如原来的1.3在排序前在索引1,排序后变为了索引0,argsort后返回的是索引1

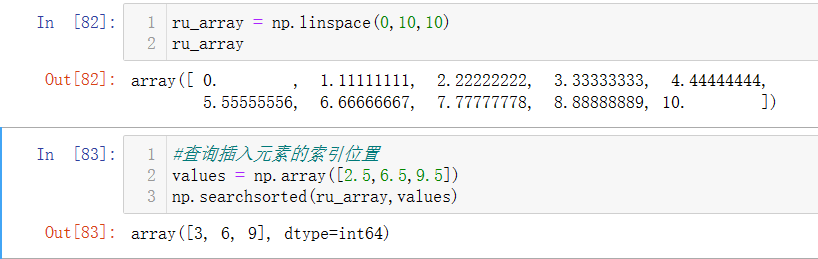
np.linspace(m, n, i)
返回的是m到n的i个元素的数组,如下图,np.linspace(0,10,10)从0到10的十个数。
np.searchsorted(数组1,数组2)
返回的是数组2插入到数组1中的元素索引位置,如下图,2.5,6.5,9.5插入到ru_array中的索引位置分别为3,6,9。
np.lexsort()
返回排序后的索引位置,具体示例如下
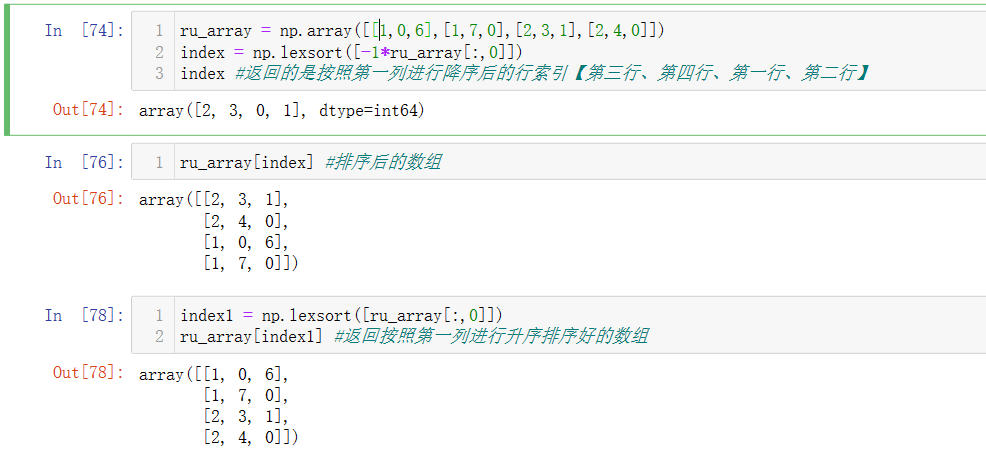
数组形状操作
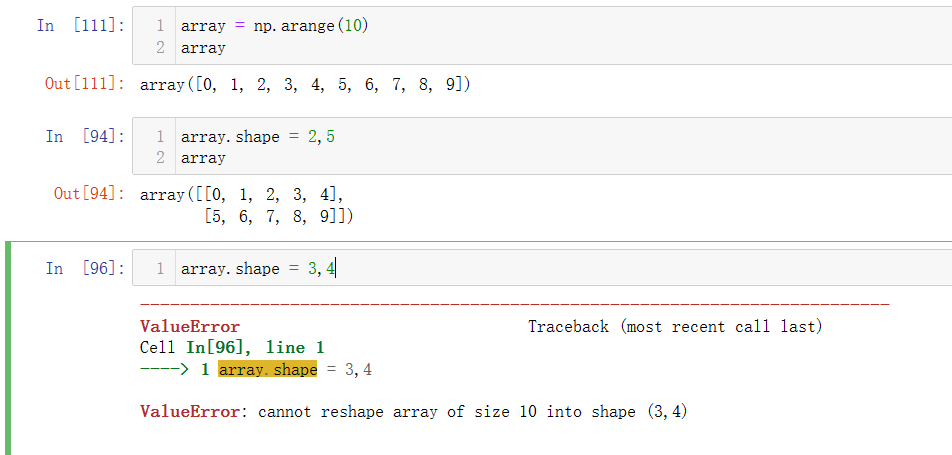
- array.shape = XX,XX ,可以直接改变数组形状,如下将一维数组按照顺序转换为二维数组,但是转换前后的数组元素个数应当一致,如果shape设定的数值乘积超出或不足会提示ValueError报错。
- np.newaxis可以给数组单纯地增加维度,如下array由一维数组转换为二维。

array.squeeze():
可以给array减少维度,如上面使用newaxis增加为二维数组后,使用squeeze使得array又转为一维数组。

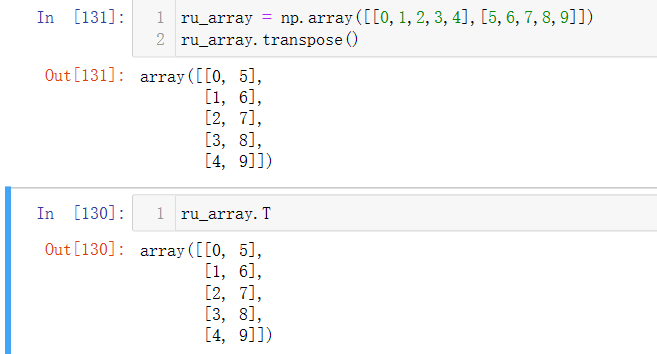
array.transpose()
矩阵转置操作,如下矩阵  转置为
转置为 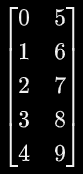 ,array.T也可以完成转置操作,
,array.T也可以完成转置操作,
数组拼接
np.concatenate((a,b))
用于把数组a与数组b数据拼接在一起(a,b都是二维数组,拼接后也为二维数组),这里参数axis默认为0表示按列拼接,axis=1表示按行拼接

np.stack((d,e))
是另一种拼接方法,原始数据是一维的,拼接后是二维,类似还有hstack与vstack操作,分别表示水平与竖直的拼接方式。在数据维度为1时,它们的作用相当于stack,用于创建新轴,而当维度大于或等于2时,他们的作用相当于concatenate,用于在已有轴上进行操作。示例如下:

array.flatten()
可以将多维数组拉平,转为一维数组。

创建数组函数
创建数组最直接的是np.array(),但是应用场景不同,需要创建的数组也不一样。
较常见的是np.arange(开始值,结束值,步长),可以自己定义数组取值区间与间隔,此外还有其他一些方法创建数组:
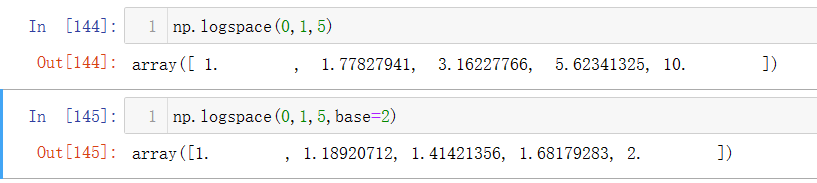
np.logspace(start,stop,num,base)
形式与arange类似,其中start为开始值,stop为结束值,num为个数,而base为底,base如果不强调,默认以10为底。如下图第一个程序表示从10的0次方到10的1次方取5个数,第二个程序表示从2的0次方到2的1次方取5个数。
np.r_[起始:结束:间隔]
快速创建行向量
np.c_[起始:结束:间隔]
快速创建列向量

np.zeros()
创建零矩阵,(3)表示创建数组为一维,包含三个元素;(3,3)表示创建3X3的零矩阵

np.ones()
表示创建单位矩阵,元素都为1,用法和zeros一样

np.empty()
表示创建空的矩阵,**array.fill(m)**表示用数值m进行填充。

np.zeros_like()
表示初始化一个零矩阵,让它和某个数组维度一致

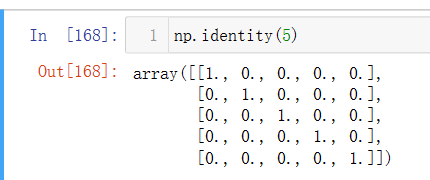
np.identity(m)
表示创建一个m行m列的矩阵,只有对角线有数值,并且为1
随机模块random
初始化参数、切分数据集、随机采样等操作都会用到随机模块,对于深度学习参数设置有很好帮助。
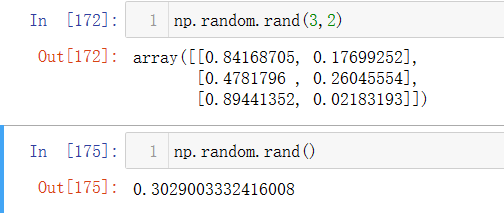
np.random.rand()
可以创建一个随机矩阵,如下图np.random.rand(3,2)创建了一个3行2列的随机数矩阵;如果括号中不填入参数,那么只会返回一个随机数。
np.random.randint()
返回随机整数的矩阵,如np.random.randint(10,size=(5,4))表示返回一个五行四列的数组,元素范围为【0,10);如np.random.randint(0,10,3)也可以指定区间0-10与个数3

np.random.normal()
返回一组符合高斯分布的概率密度随机数,函数语法np.random.normal(loc,scale,size):loc为概率分布的均值,scale为概率分布的标准差,size为随机数个数,

np.set_printoptions(precision)
该方法用于全局设置,参数precision为控制结果输出的小数位数。

np.random.shuffle(array)
用于对数组进行洗牌操作,有时候生成的数据集总是按照顺序排列,我们需要一种随机的顺序完成机器学习,因而可以借助该函数打乱顺序。

np.random.seed()
随机种子函数,当我们希望对数据随机操作时,但又不想每次操作数据都变个样,所以可以使得每次随机结果都相同,如下图,设定的随机种子为100,当进行normal随机操作时返回的都是如下结果,随机种子数值可以随便设置。

在某些情况下最好指定唯一的随机种子,避免由于随机差异对结果产生影响。
文件读写
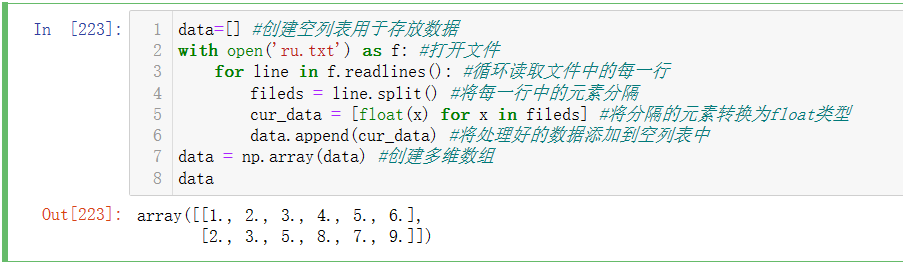
如果用python进行数据读取,代码要比较麻烦繁琐,Numpy相对简单一点,此外后续的Pandas中也有关于数据读写的方法,都非常简单,这里我们先熟悉一下Numpy中的文件读写的基本操作。
首先创建一个文本文件,**%%writeflie <文件名>** 为Notebook的魔法指令,相当于写了一个文件

np.loadtxt()或np.load()
传统的Python读取文件,操作如下:
使用Numpy完成上述步骤:
使用np.loadtxt(‘文件名’)方法,只需要一行就可以完成!

如果文本带有分隔符,也可以读取:
如下文本文件中元素以“,”分隔,np.loadtxt()方法中的delimiter参数可以设置识别的分隔符。

等等loadtxt的功能请看API文档,这里不做过多介绍。
np.savetxt()
可以在当前路径创建一个文件或者在原有文件中写入数据,可以指定保存格式参数fmt与分隔符参数delimiter


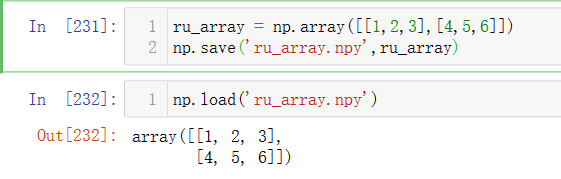
在Numpy中还有一种“.npy”格式,可以通过np.save()把数据保存为ndarray的格式,这种方法可以把程序运行结果保存下来,需要时再通过np.load()读取.npy文件即可,非常便捷,如下是具体示例:

总结
学习过程并不需要记住所有函数,只需要熟悉其基本使用方法即可,在实际使用时遇到困难可随时翻阅文档查询用法,对于各种工具包要边学边用,边用边学。
上述展示的代码如有需要,点此处下载dl-note-numpy.ipynb
- 标题: 数据挖掘学习记录(一):科学计算库numpy
- 作者: 狮子阿儒
- 创建于 : 2023-04-29 22:10:11
- 更新于 : 2024-03-03 21:28:49
- 链接: https://c200108.github.io/blog/2023/04/29/数据挖掘学习记录(一):科学计算库numpy/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。