

数据挖掘学习记录(二):数据分析处理库Pandas

数据分析处理库Pandas
Pandas工具包是专门用作数据处理与分析的,其底层计算其实都是由Numpy来完成的,再把复杂的操作全部封装起来,使用起来十分高效,使得使用者可以更专注于数据处理与分析。在数据科学领域,无论哪个方向都是跟数据打交道,所以Pandas非常实用,本文章主要介绍Pandas的核心数据处理操作,并通过实际数据集来演示如何进行数据处理与分析任务。
数据预处理
利用Pandas做数据预处理,那必然先要导入相关库。
import pandas as pd
和Numpy导入方法类似,并且将pandas模块命名为pd,方便后续写代码
本节主要了解pandas的数据读取与DataFrame结构的基本数据处理操作。
数据读取
我们在上一篇文章了解到,Numpy读取文件是利用loadtxt()或load()获取文件内容,pandas也有自己独特的方法。
pandas读文件需要根据文件类型的不同使用不同的方法,如下是对这些方法的汇总:
- pd.read_csv():读取CSV文件
- pd.read_excel():读取Excel文件
- pd.read_sql():读取SQL数据库中的数据
- pd.read_json():读取JSON文件
- pd.read_html():读取HTML文件中的表格数据
- pd.read_clipboard():读取剪贴板中的数据
- pd.read_pickle():读取pickle格式的数据
- pd.read_feather():读取feather格式的数据
- pd.read_parquet():读取parquet格式的数据
- pd.read_msgpack():读取msgpack格式的数据
方法很多,但常用的就那几个:read_csv、read_excel、read_sql、read_json,我们在一些数据集网站上可以看到大部分Dataset都是CSV格式的,CSV文件的通用性非常强,所以后面学习以CSV文件为主,
pd.read_csv()
pd.read_csv(‘文件名’),本文的数据集来自于Kaggle平台 ,是一份真实美国房地产数据,包含10个特征,共计10万个样本。read_csv通过Notebook读取CSV文件可以直接展示成表格形式。
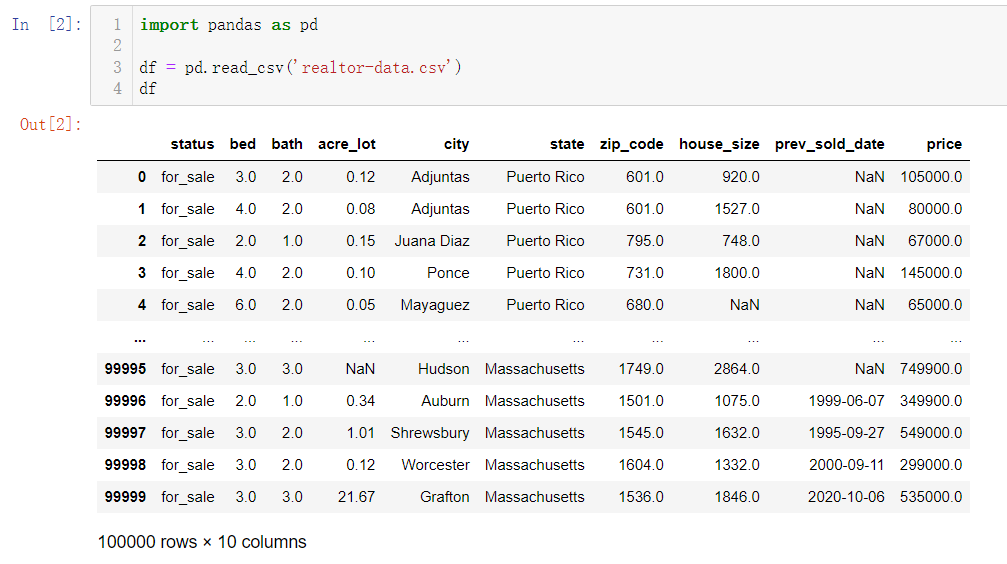
df.head()
可以展示读取数据,默认展示前五条。如果想展示更多数据,则可以在head()函数中指定数值,head(10)表示展示前10条数据。

df.tail()
用法和head()一致,不过tail()是展示读取最后面的数据

DataFrame结构
Numpy记录中我们了解到Python有自己的四种基本类型,而Numpy有自己的ndarray多维数组。现在学习pandas,它也有自己的数据结构DataFrame。
那DataFrame是什么样的呢?
其实上面展示的数据就是DataFrame结构,它是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引。
CSV文件通过read_csv读取后就会转换为DataFrame格式,这也是我们为什么命名df的原因(DataFrame缩写)
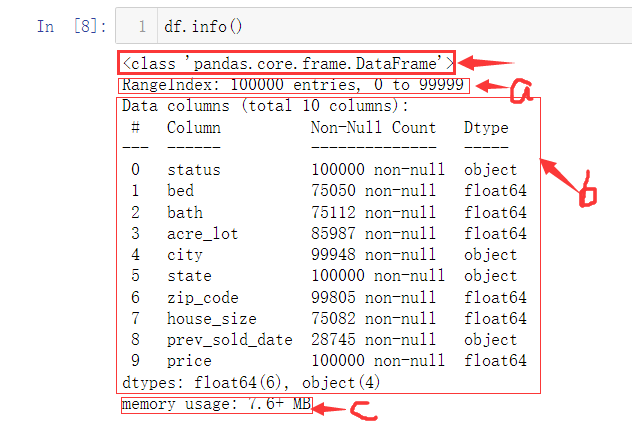
df.info()
该方法可以检查读取数据的部分信息,pandas.core.frame.DataFrame就表示数据类型为DataFrame,下面箭头a指的是数据样本规模,箭头b指的是各列特征的基本信息及数据类型,箭头c指的是文件所占空间大小
除了使用info查看详细数据外,还有很多能调用的属性如下:
df.index
单独查看数据样本规模

df.columns
单独查看数据的每列特征的名字

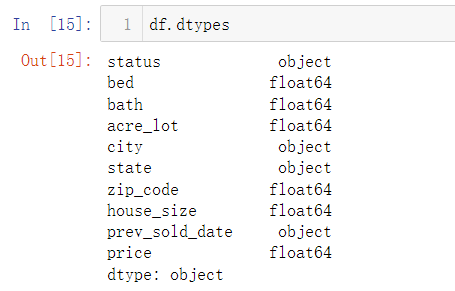
df.dtypes
单独查看各列数值的数据类型,object表示Python中的字符串
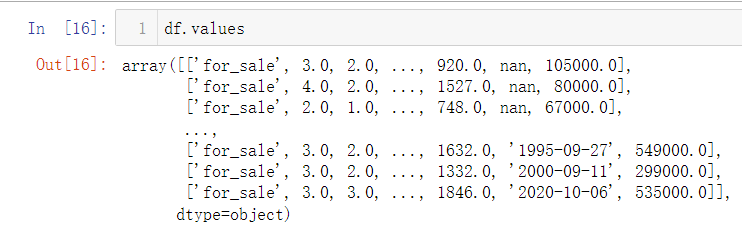
df.values
直接取得数值矩阵
其他更多属性详细使用方法请见Pandas官方文档
数据索引
在引入数据后,我们需要查找具体哪条数据或某一列指标等,该怎么办呢?现在Pandas给出了许多简便方法:
df[‘特征名’]、变量名[a:b]
df[‘特征名’]表示单独查找该特征下的所有值、变量名[a:b]表示该特征值中索引a-b的数据,如下 【0,5)数据0-4共五个数据。

如果说DataFrame类似于二维数组,那上述单独的bed特征是不是就类似于一维数组呢?
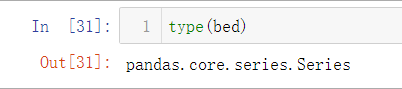
其实Pandas除了基本DataFrame结构外,还有一种数据结构为Series,由索引(index)和列组成,查询bed的结构发现为pandas.core.series.Series,证实bed为Series类型。
如果想对样本数据进行计算整理等操作,DataFrame和Series并不能很好的参与,而是需要将结果单独拿出来,上述讲到的df.values返回结果就是二维数组,Series.values结果便是一维数组。这些数组结果也正是因为Pandas中的很多计算和处理等操作都是由Numpy完成的。

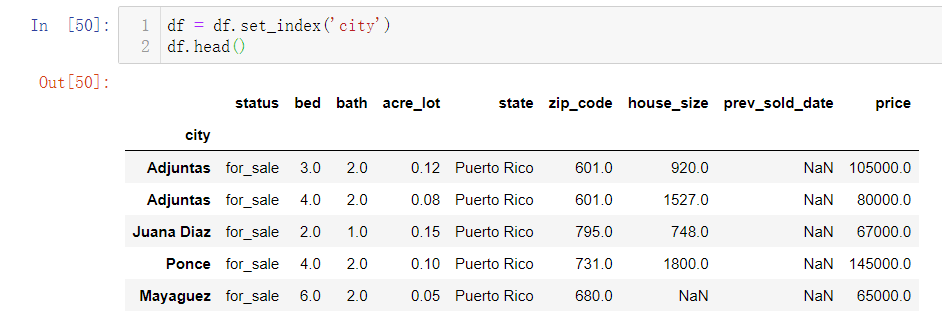
df.set_index(‘标签’)
pandas读取CSV文件后,会自动在第一列设置索引,如果我们不想使用1,2,3之类的索引,而使用其它的关键字作索引,我们可以用set_index(‘标签名’)来设置索引,如下便设置city标签为索引:
上述设置了city索引后,如果我们想查询某个城市的一些信息,我们可以如下操作:使用df[‘bed’]只显示bed标签的数据,在使用bed[‘Adjuntas’]是找到Adjuntas索引的bed信息。

df[‘标签’] [‘索引’]
查询某些标签的具体索引。如下:

Pandas中还有两个特别的函数用来帮忙查询数据:
df.iloc()与df.loc()两种方法效果类似,工作原理都是根据行与列交叉定位数据,换言之和定位二维坐标轴中的点一样,由(x, y)组成。
不同之处无非在于列的表示方法,iloc()只能使用列的索引位置,而loc可以使用列的标签名。loc在使用起来更个性化
df.iloc[]
用索引位置找数据
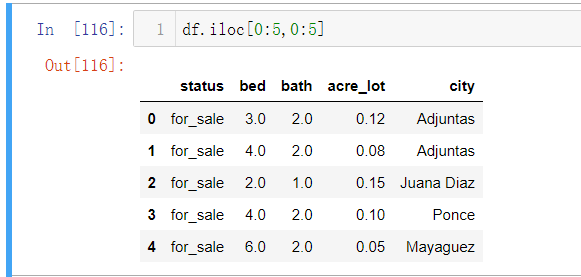
df.iloc[x,y] 表示定位x行 y列的数据,而X与Y不一定是一个数,它也可以是一个范围,如
- df.iloc[0:5,0:5]表示前五行前五列的数据

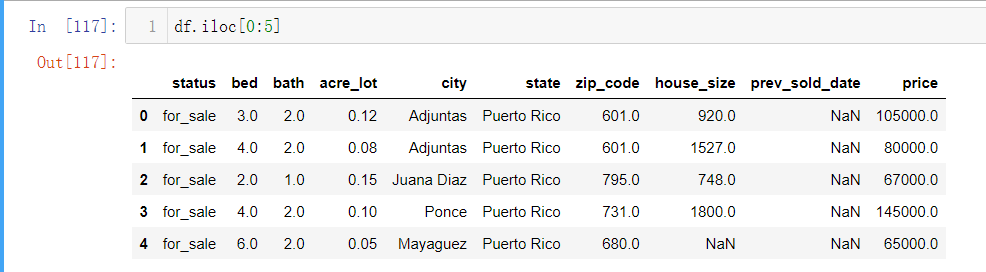
- df.iloc[0:5]:括号里只有一个范围则默认显示指定行+所有列的数据(对比上面df.iloc[0:5,0:5])
- df.iloc[0]定位第一行的数据信息
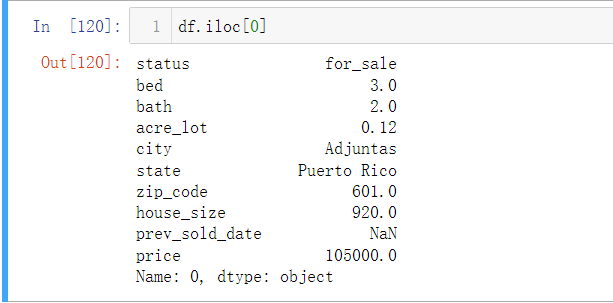
df.loc[]
用索引标签找数据
df.loc[x,y]表示定位x行 列名为y的数据,其中x为行索引,y表示列标签名(一个或多个)
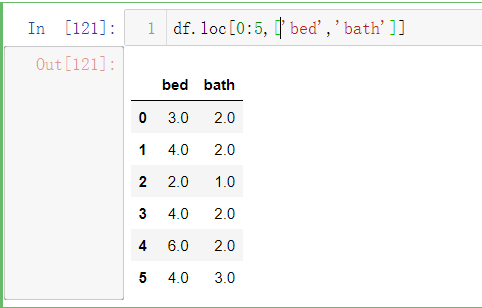
- df.loc[0:5,[‘bed’,’bath’]]表示前五行标签为bed与bath的数据
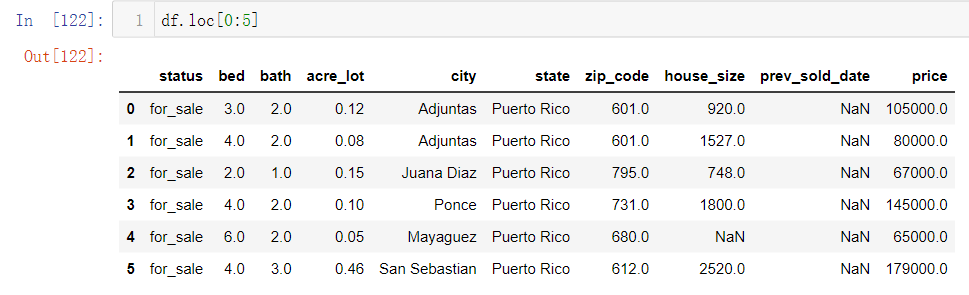
- df.loc[0:5]默认显示前五行的全部数据信息
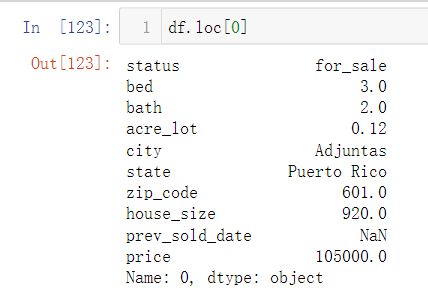
- df.loc[0]表示第一行数据
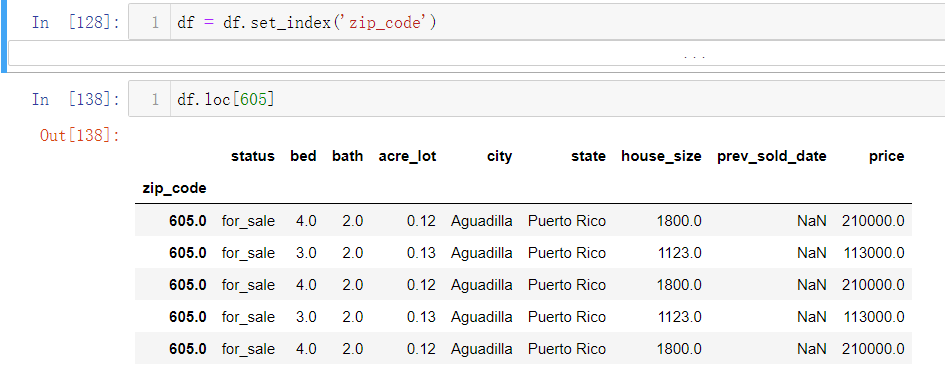
- df.set_index(‘zip_code’)将行索引改为邮编,df.loc[‘605’]定位605邮编有哪些数据
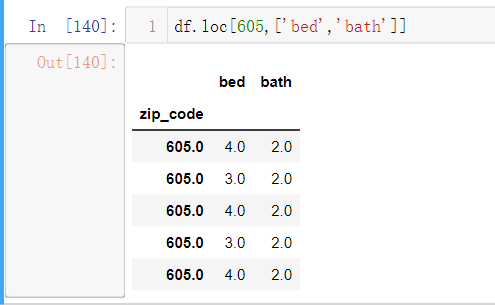
- df[605,[‘bed’,’bath]]表示查找605邮编,标签为bed、bath的数据(和上述df.loc[0:5,[‘bed’,’bath’]]类似,只不过行索引换成了邮编号)
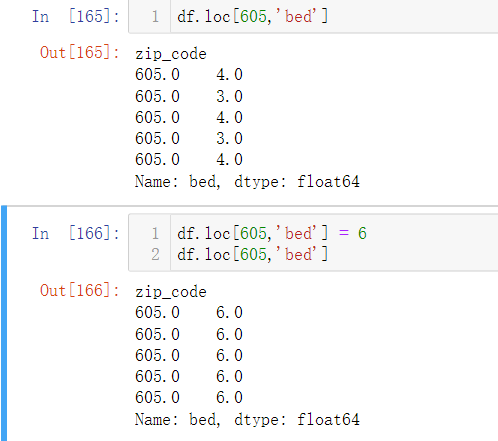
- df.loc[605,’bed’]=6表示找到该行列的数据,然后对它赋值
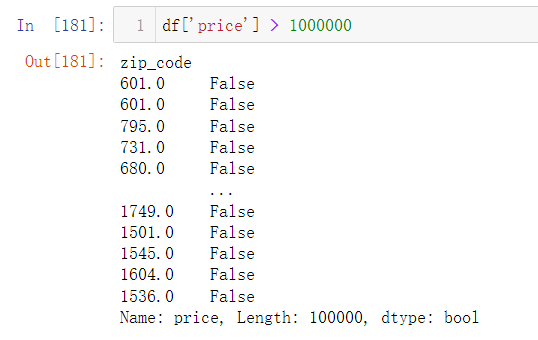
在Pandas中Bool类型同样也可以作为索引,可以根据=、< 、 >来筛选符合一定条件的数据,举个例子如下
df[‘price’]>1000000 : 筛选房价大于1000000美金的房屋邮编
df[df[‘price’]>1000000].head(5):展示前五条符合房价大于100万美金的房屋数据。
df[df[‘city’]==’penuelas’].head(5):展示前五条位于penuelas城市的房屋数据。
df.loc[df[‘city’] == ‘Penuelas’,’price’].mean():计算位于Penuelas城市的房价平均值
(df[‘price’] > 1000000).sum():统计所有房价大于100万美金的房屋数量
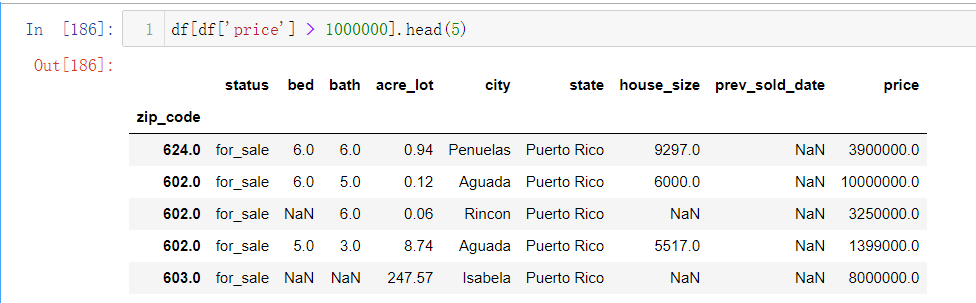
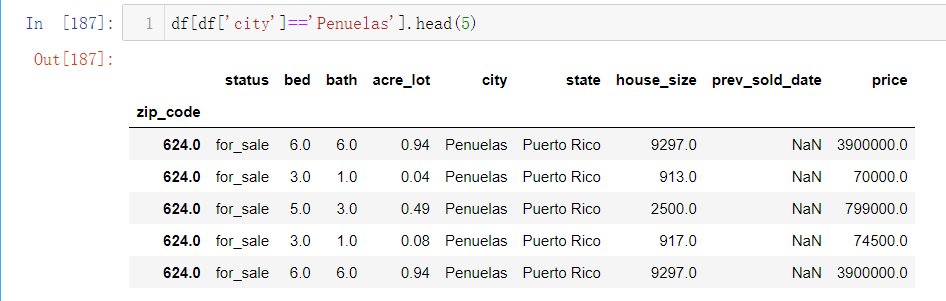


通过上述的一些例子,我们可以看到Pandas中的数据索引方式多种多样,非常灵活,在面对大样本数据时,也可以按照要求方便地定位数据。
创建DataFrame
之前我们都是用读取文件的方式获得DataFrame结构数据,那该如何创建自己的DataFrame数据呢?
最简单的方式就是创建一个字典结构,其中Key表示列名,Value表示各个样本的实际值,然后通过pd.DataFrame()将字典转换为DataFrame结构。操作如下:
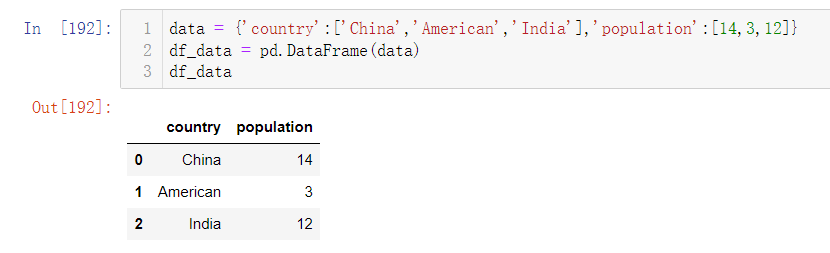
使用Pandas做数据分析时,发现NoteBook显示行数较少,我们可以通过相关的函数对数据显示做设置,具体一些去Pandas官方文档查询即可。
Series操作
上面也讲到了Series结构的一些,和DataFrame区别就是Series相当于一维的。单独读取某列数据,那就是Series结构。
创建Series
pd.Series(data=值, index=索引):将值列表与索引列表合并转换为Series结构,如下:

查找
Series的loc()与iloc()方法:和DataFrame类似。

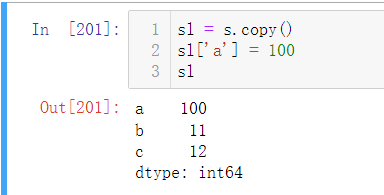
修改实际值
修改操作可以直接对查找到的数据赋值:
也可以使用replace()函数修改:to_replace参数表示要修改的数据,value表示修改后的数据,inplace=True表示修改好后赋值,inplace=False表示只执行打印操作,不赋值

修改索引
可以直接给索引赋值:

实际情况中索引数量往往非常多,无法一一写出来,因而用rename()方法可以很好地替换索引:参数index={‘原始值’:’更新值’},inplace=True表示修改好后赋值,inplace=False表示只执行打印操作,不赋值

增加数据
创建个新的Series,然后原有Series与新Series拼接,然后形成的Series就是增加后的所有数据。如下:用pandas.concat()进行拼接(如果拼接对象为DataFrame结构数据,还需要考虑参数ignore_index=True:忽略索引;sort=False:列的顺序维持原样, 不进行重新排序;axis=1:横向合并),s3[‘j’]=500直接增加实际值500的j。
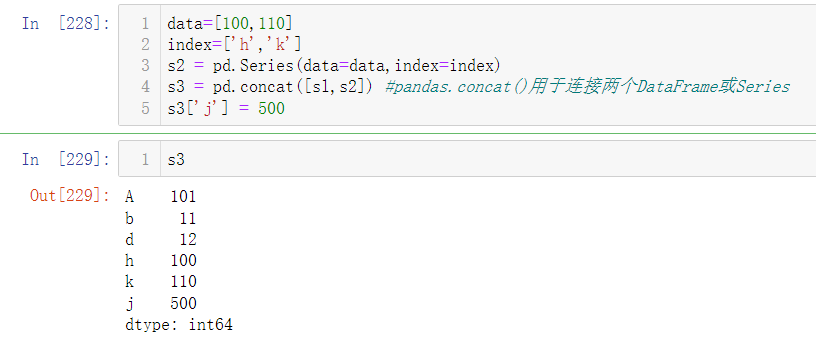
DataFrame拼接:
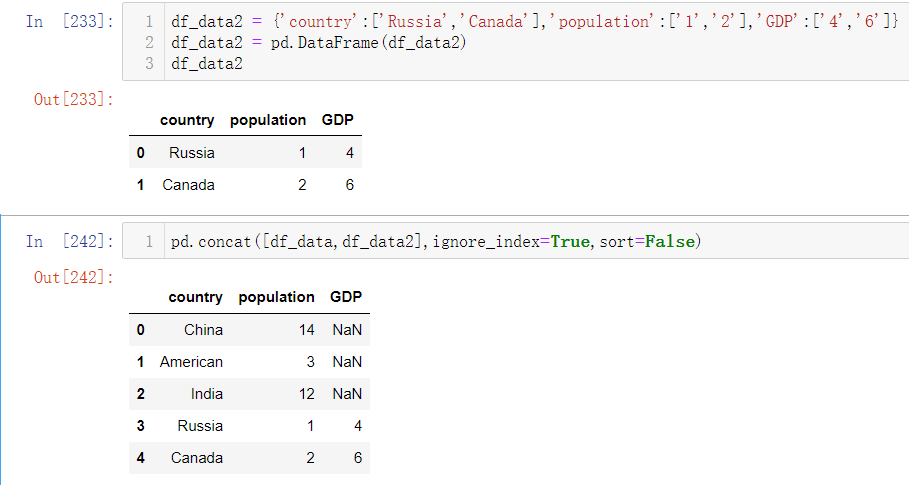
Series拼接使用ignore_index=True后,原有的’A’,’b’,’d’,’h’,’k’被替换成了0~4的索引。

删除操作
- del 变量名[索引]
- 变量名.drop([索引], inplace=True)

也可以删除整列,方法相同。
数据分析
DataFrame也可以和Numpy一样对数据进行计算,如下:

统计分析
在对数据进行分析时,样本数据的各种属性是常常分析的对象,数据特征的分析指标比较多,例如均值,最大值,最小值等均可以直接调用其属性获得。
df.sum()
先创建一个简单的DataFrame,传入数据,指定行索引与列索引。可以对每一列与每一行进行求和计算,参数axis=0或1分别对应列或行,默认axis=0。

df.describe()
df.describe()方法可以详细展示样本数据的各类属性,
- count:个数
- mean:均值
- std:标准差
- min、max:最小值、最大值
- 25%、50%、75%:分别为较小四分位数、中位数、较大四分位数,所谓四分位数(Quartile),是指在统计学中把所有数值由小到大排列并分成四等份,处于三个分割点位置的数值。

使用describe方法可以很好地观察数据是否存在问题,如年龄、房价等特征是否存在负数值,数据是否存在缺失值。
df.cov()
协方差矩阵

df.corr()
相关系数

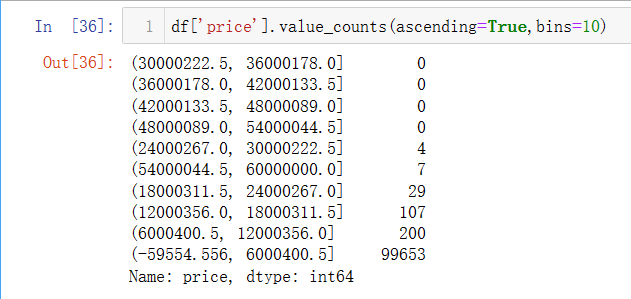
df.value_counts()
对样本数据的实际值进行分组计数,参数ascending=True表示指定顺序,从小到大;对于组数特别多的数值型数据,参数bins=10表示将数据分为10组。
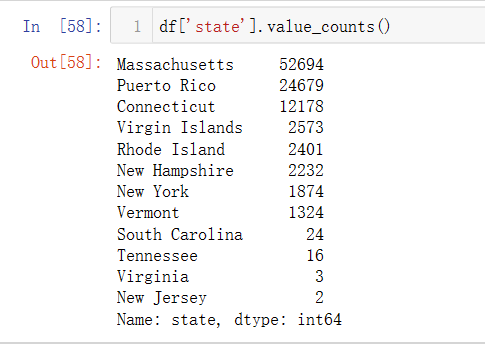
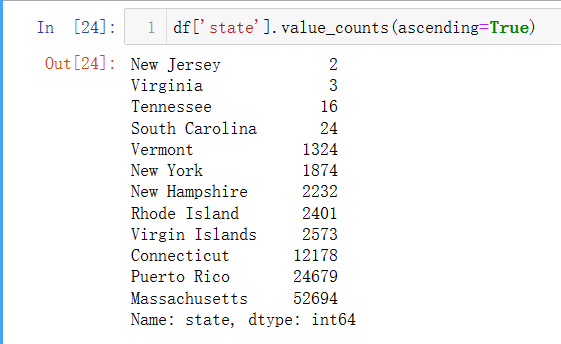
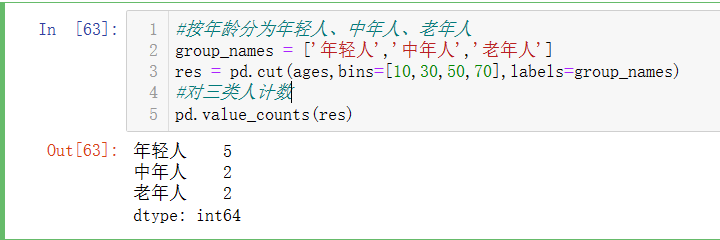
pd.cut()
对连续型的数值进行分箱操作,常用于对所有数值进行分档或分类操作。
形式pd.cut( x, bins, right=True, labels=None, retbins=False, precision=3, include_lowest=False, duplicates=’raise’ ):
- x:一维数组
- bins:整数,标量序列或者间隔索引,是进行分组的依据
- right:布尔值,默认为True,表示包含最右侧的数值(左开右闭)
- labels:数组或布尔值,指定分箱的标签
- retbins: 是否显示分箱的分界值。默认为False,当bins取整数时可以设置retbins=True以显示分界值,得到划分后的区间
- precision:整数,默认3,存储和显示分箱标签的精度。
- include_lowest:布尔值,表示区间的左边是开还是闭,默认为false,也就是不包含区间左边。
- duplicates:如果分箱临界值不唯一,则引发ValueError或丢弃非唯一
具体示例如下:

在机器学习中将连续型数据离散化是一种常用的套路。
pivot数据透视表
pd.pivot(df,index,columns,values)
类似于excel的数据透视表,返回DataFrame按指定行(index)和列(column)重构的数据透视表,返回的数据透视表也是一个DataFrame。
- 参数df:DataFrame数据
- 参数index:行索引标签,可以为单个标签,也可以多个标签组成的列表。
- 参数columns:列索引标签,可以为单个标签,也可以多个标签组成的列表。
- 参数values:对应实际值
创建如下DataFrame数据,包括种类、月份、数量三个特征,每个特征都有12个实际值。

使用df.pivot()实现数据的重构,以Category为行索引,以Month为列索引,以Amount为实际值,建立了一个新的DataFrame。因此可以看出pivot作用:原本杂乱的数据按照规则做重新整理。

形成的透视表就是DataFrame,同样可以进行运算操作等

- 注意!当行索引和列索引相同时,实际值只能有一个
官方文档给出例子:
图中行索引为’one’,列索引为’A’的数据有两条,实际值分别为1、2,这种情况存在冲突,会报错:索引包含重复条目,无法重新整形。
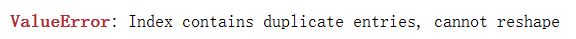
- 此外,行索引与列索引不能同样,否则会报错:
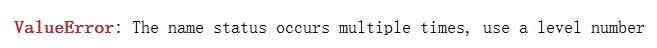
groupby操作
groupby函数是统计分析中经常用到的函数,用法非常灵活,可以指定许多参数,也可以和DataFrame一样使用多种运算与分析操作,但是也非常容易出错,使用前一定先设想需要什么样的结果,然后再去选择合适的参数,否则在编写程序时容易杂乱混淆。
df.groupby()
下图是groupby的工作过程,将原本的DataFrame拆分,按照拟定规则分成不同组,最后形成多个DataFrame组成的DataFrameGroupBy类型,图片来自于Pandas教程 | 超好用的Groupby用法详解 - 知乎 (zhihu.com)

根据一定条件做分组操作,
- 创建一个DataFrame:

- 为计算每一类别的数据有多少个,使用传统的循环分组,操作如下:
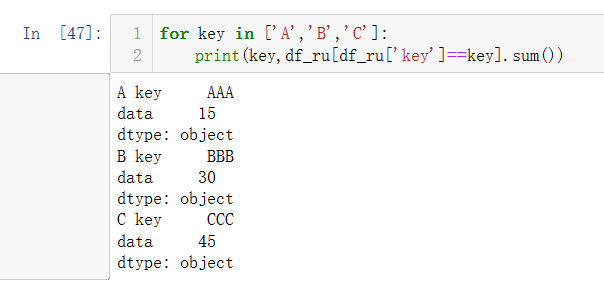
- 如果使用groupby操作,只需要一行代码,按照’key’进行分组如下:

- 使用groupby对原有df分组后的数据类型不是单纯的DataFrame,而是多个子DataFrame组成在一起的类型,如下:

直接打印分组后的数据,会返回一个DataFrameGroupBy类型,后面0x00表示该对象是可迭代的,如下:

查看分组数据
groups
使用groupby().groups可以查看分组结果,如下:

get_group()
使用get_group()可以对分组后的数据指定读取某一组的数据,如下:

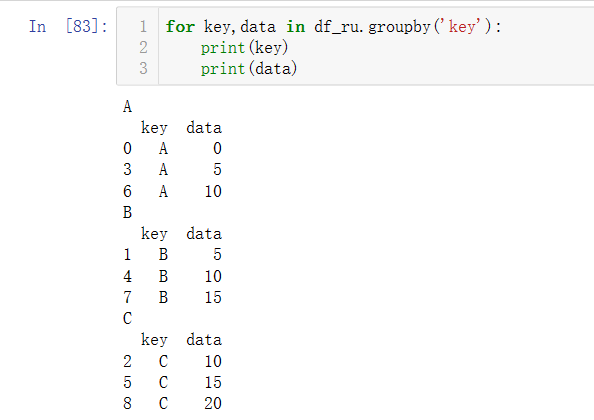
遍历分组数据
for循环遍历,操作如下:
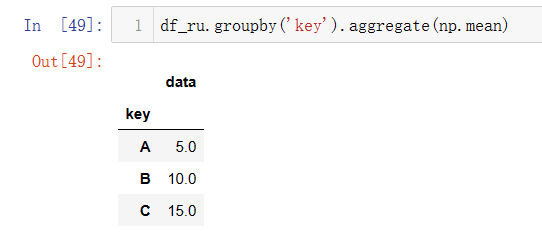
groupby().agg()
通过 aggregate()或agg() 函数可以对分组对象应用一个或多个聚合函数,多个聚合函数表示类似agg([np.size,np.mean,np.std])如下:
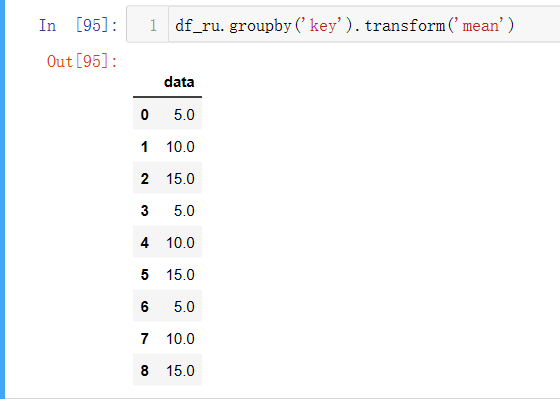
groupby().transform(‘ ‘)
transform方法会按照原本,详细使用方法请见:新手向——理解Pandas的Transform - 简书 (jianshu.com)
groupby.filter()
通过 filter() 函数可以实现数据的筛选,该函数根据定义的条件过滤数据并返回一个新的数据集。
groupby.apply()
常用函数操作
Merge函数
该函数常用于两个DataFrame数据进行左右合并。区别于concat()的纵向连接,Merge实现数据的横向连接。
形式 pandas.merge(left, right, on, left_index, right_index, how, suffixes, indicator) :
left:用于合并的左侧DataFrame
right:用于合并的右侧DataFrame
on:设置主键字段,可以设置一个或多个
left_index, right_index:布尔类型,默认False,这两个参数要么全部False,要么全部True
how:连接方式,默认内连接(inner),其他连接方式:外连接(outer)、左连接(left)、右连接(right)。
suffixes:区分不同表中相同列来自哪个DataFrame,默认会设置后缀为
_x,_yindicator:显示拼接后的表中哪些信息来自哪个表
创建一个新的DataFrame,如下:

合并left与right两个表,左右合并,on设置主键为’key’
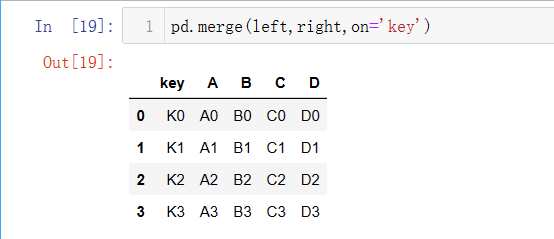
left_index/right_index显示相同列的左右索引,字段key分为left表的key_x与right表的key_y

设置参数suffixes,将key_x、key_y修改为key_left、key_right

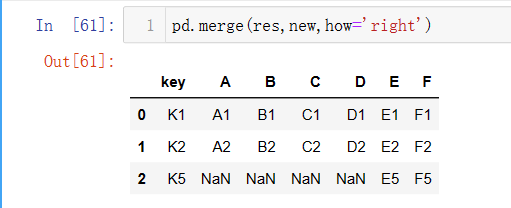
新建一个DataFrame,变量名为new;原来的left表与right表合并成res表;然后将res与new合并,how默认是内连接。
4行与2行合并,最后只有K1与K2的行显示了,因为内连接只会显示同一主键下左右两表都有数值的行。K0与K3这两行数据没有’E’,’F’的数据,不完整。

外连接:按照行和列显示两个表中的所有信息,而不存在的数据也会用NaN来填充。如K0,K3没有E列与F列的数据,K5没有A、B、C、D列的数据。

左连接:保留所有左表的信息,把右表中主键与左表一致的信息拼接进来,标签不能对齐的部分,用NAN进行填充,而左表没有的主键将不会显示,如字段K5只在new表中,不在res中。

右连接:保留所有右表的信息,把左表中主键与左表一致的信息拼接进来,标签不能对齐的部分,用NAN进行填充,而右表没有的主键将不会显示,如字段K0,K3只在res表中,不在new中。
通过外连接显示所有信息后,indicator参数用于设定显示拼接后的表中哪些信息来自于哪一个表格,其中both表示该行数据来自左右两个表,left_only表示该行数据只来自左表,right_only表示该行数据只来自右表。

排序操作
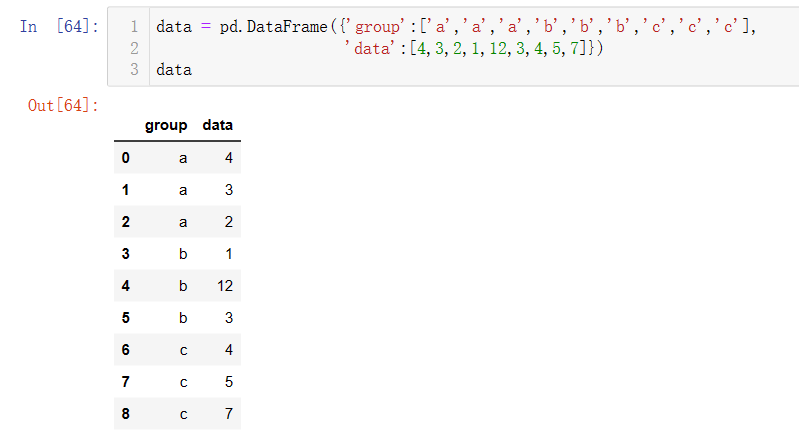
创建一个新的DataFrame,字段为group与data
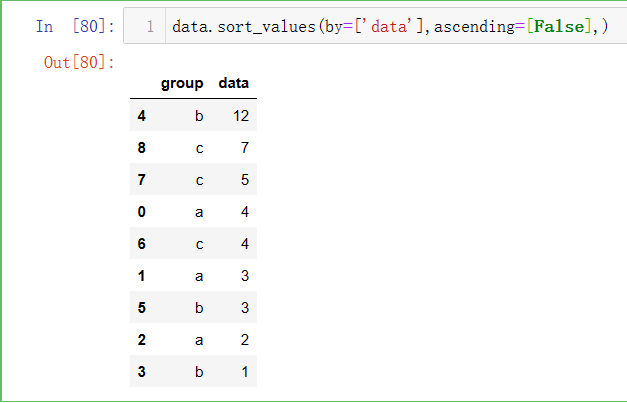
df.sort_values(by, ascending)
能够实现指定列数据的升降序排序,
参数by:指定排序的字段,可以为一个或多个字段。
参数ascending:布尔类型,默认为True,按升序排列;False代表按降序排列。
多字段时,哪个字段在前就先排列哪个,然后相同数据会成一组,按规则排序,同时每一组中的数据也按规则排序,ascending位置与by的位置一一对应,区分以下两种情况:
(1)group按照升序排,data按照降序排;先排列group,如果有相同数据再排列data
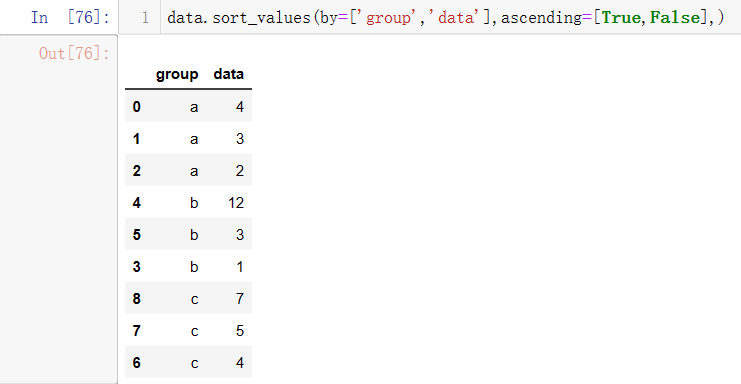
(1)data按照升序排,group按照降序排;先排列data,如果有相同数据再排列group

重复值处理
df.drop_duplicates()
去重函数df.drop_duplicates(subset=[‘A’,’B’,’C’],keep,inplace)
- 参数subset:要去重的列名,默认为 None。
- 参数keep:有三个可选参数,分别是 first、last、False,默认为 first,表示只保留第一次出现的重复项,删除其余重复项,last 表示只保留最后一次出现的重复项,False 则表示删除所有重复项。
- 参数inplace:布尔值参数,默认为 False 表示删除重复项后返回一个副本,若为 Ture 则表示直接在原数据上删除重复项。
创建新的DataFrame:

不设置参数,表示直接将大部分完全重复的行删除,只保留第一个重复项(默认):

设置subset为k1,表示只对k1列去重,不会处理k2的重复项,如k1中只有one、two两个值,结果就只保留两个。

keep设置为False,表示将完全删除重复项,不会保留。

缺失值处理
增加列
df.assign()
用于往数据中添加新的列,
如下,创建一个新的DataFrame,使用assign函数往df中添加新的列ration:

df.insert()
df[‘新列名’]=值
df.reindex()
df.merge()
df.concat()
df.loc(:, 新列名) = 值
缺失值
创建一个包含缺失值的DataFrame,使用numpy.nan可以生成NaN缺失值。

df.isnull()
会直接对表格进行判断,缺失值用False表示,有数值就用True表示。

any()函数:检查行或列中是否存在缺失值,只要有一个缺失值,行或列就会表现为True,如下:

df.fillna(填充值)
对缺失值进行填充,实际问题中填充值更常使用的是均值、中位数等指标,还需要根据具体问题具体分析,如下:

apply自定义函数
将DataFrame或Series数据作为实参传入函数中。
DataFrame.apply(func, axis=0, raw=False, result_type=None, args=(), **kwargs),返回类型为Series或DataFrame,
- func:应用于每行每列的方法,可以是def自定义函数,也可以是lambda表达式。
- axis:0表示将函数应用于每一列,1表示将函数应用于每一行
- raw:布尔类型,默认False,将每一行或每一列作为Series传递给函数。
- args: 元组类型,需要递给func的除array/series外的其他参数。
- **kwargs:字典类型,传递给func的其他关键字参数,如果args只传递了部分参数,那kwargs可以再递补剩余的。
新建一个DataFrame:
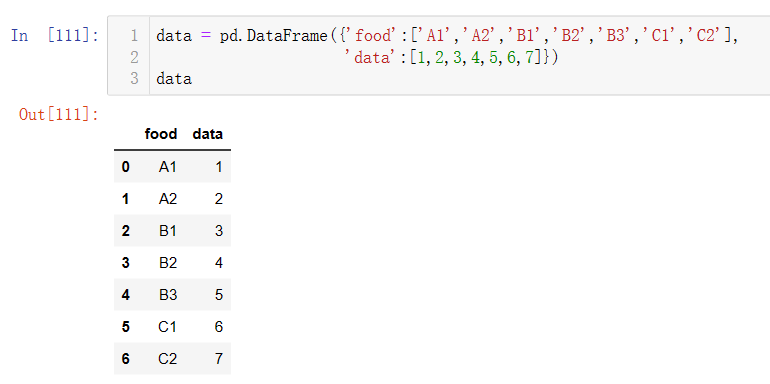
使用apply函数增加新的一列food_map,具体方法为自定义映射函数food_map,使用判断条件语句,将food标签做了分组:

时间操作
pd.Timestamp()
在机器学习建模时,偶尔会遇到时间特征,当拿到一份时间特征时,最好还是将其转换为标准格式,这样提取时更加方便一点。
如下是将字符串时间转换为datetime类型,Timestamp.month/year/day代表时间特征中的月/年/日:

可以在原Datetime格式数据直接相加减Timestamp时间特征,效果如下:原日期+5天

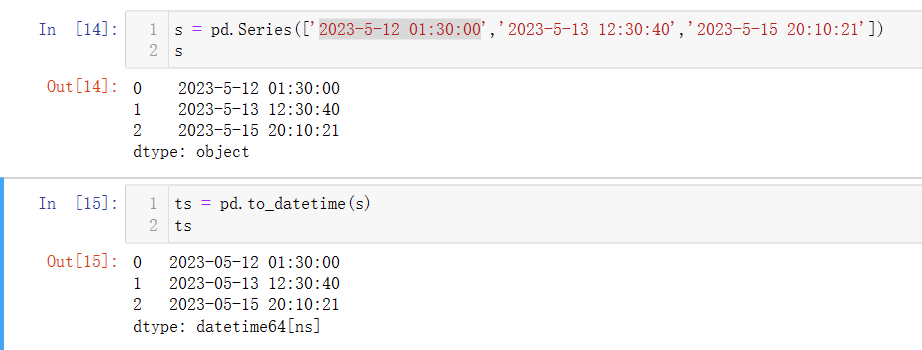
pd.to_datetime()
用于将Series或DataFrame数据中时间对象转换为datetime64类型,方便后续时间处理。如下:
df.dt.hour/minute/second/weekday:求时间特征的小时、分钟、秒数、周几:

pd.date_range()
pd.date_range(start, periods, freq)用于连续生成时间特征数据,参数start为时间格式,参数periods为生成时间特征数据格式,参数freq为相隔时间:

绘图操作
在Notebook中使用绘图操作需要先执行此命令%matplotlib inline,如下是绘制四条折线,random.randn(10,4)生成随机的十行四列的数组(十行:每条线十个点;四列有四条折线),

df.plot(axes, kind)
axes[0]为标签在x轴,axes[1]为标签在y轴,kind为图表类型,有“bar”、“barh”、“line”等
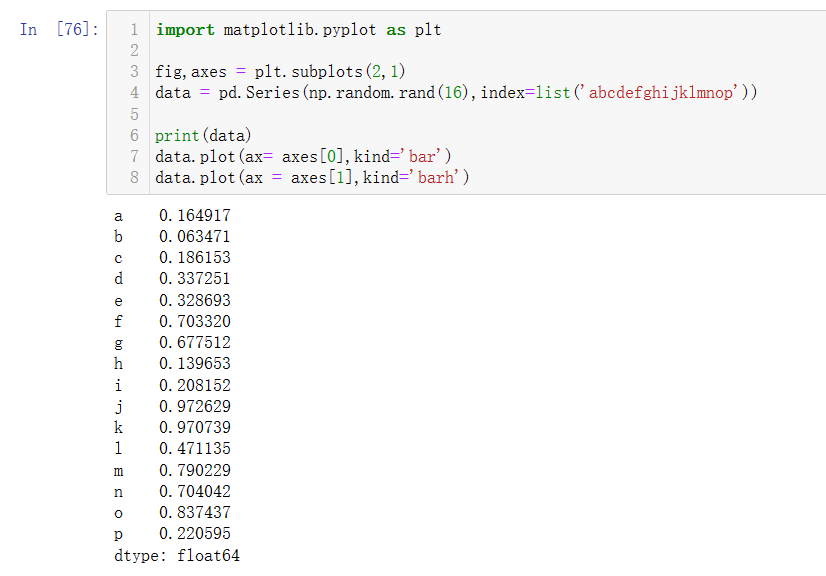
创建DataFrame数据,绘制柱形图:


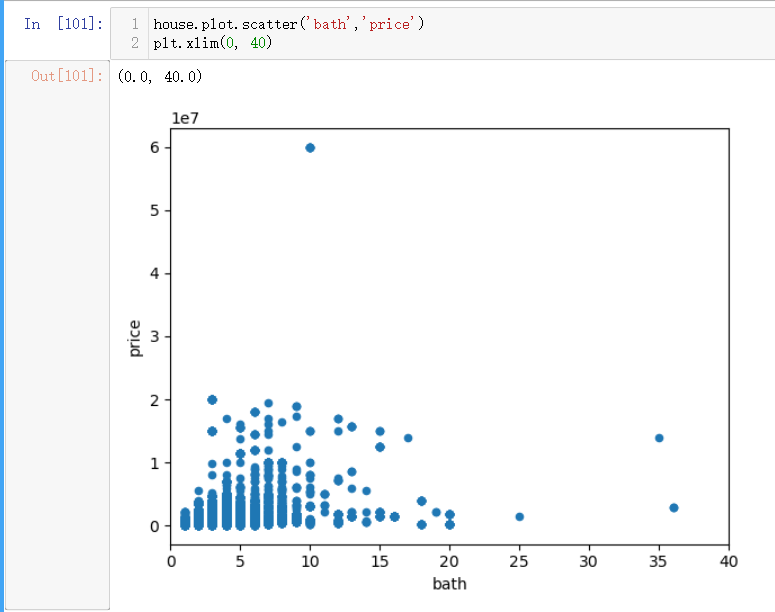
选取美国房地产数据集中特征绘制散点图:
大数据处理技巧
数值类型转换
数据集文件:realtor-data.csv
- 标题: 数据挖掘学习记录(二):数据分析处理库Pandas
- 作者: 狮子阿儒
- 创建于 : 2023-05-03 12:23:45
- 更新于 : 2024-03-03 21:41:42
- 链接: https://c200108.github.io/blog/2023/05/03/数据挖掘学习记录(二):数据分析处理库Pandas/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。