
深度学习记录(四):YOLOv5 7.0实战

官方更新了最新的YOLOv5 7.0版本,体验一下
YOLOv5环境安装
环境
anaconda
配置
过程请见深度学习记录(一):PyTorch安装
YOLOv5使用预训练模型进行检测
下载项目
下载YOLOv5项目文件,地址:GitHub-YOLOv5官方项目 ,
使用命令:
1 | git clone https://github.com/ultralytics/yolov5.git |
安装依赖
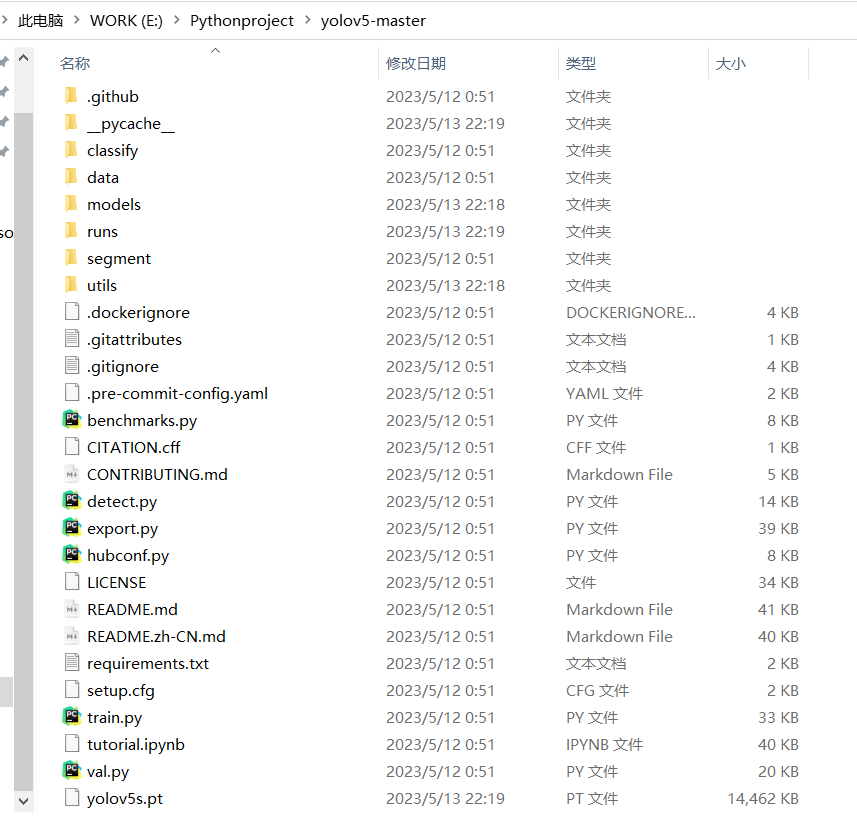
文件夹中有requirements.txt,列举项目所需依赖,
打开终端,安装依赖包
1 | pip install -r requirements.txt |
具体依赖如下,注意torch>=1.7.0,numpy可以选择==1.18.5
小试牛刀
终端输入 python detect.py,先运行一下项目测试用例,看是否能生成检测图片。

默认是使用yolov5s.pt模型检测,由于我训练过一次了,所以本地有该文件,初次训练会自动从GitHub下载,网速慢尽量挂VPN。
运行结果放到runs文件夹下:
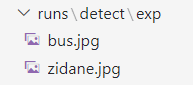
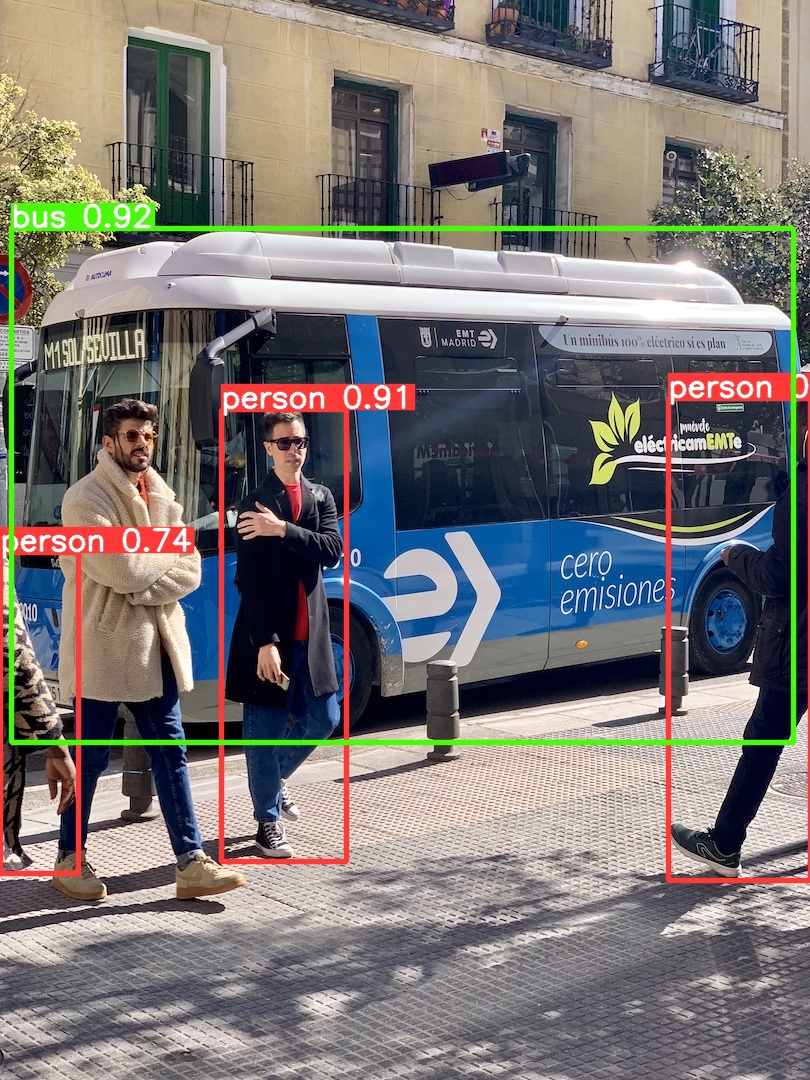
样例图bus.jpg:
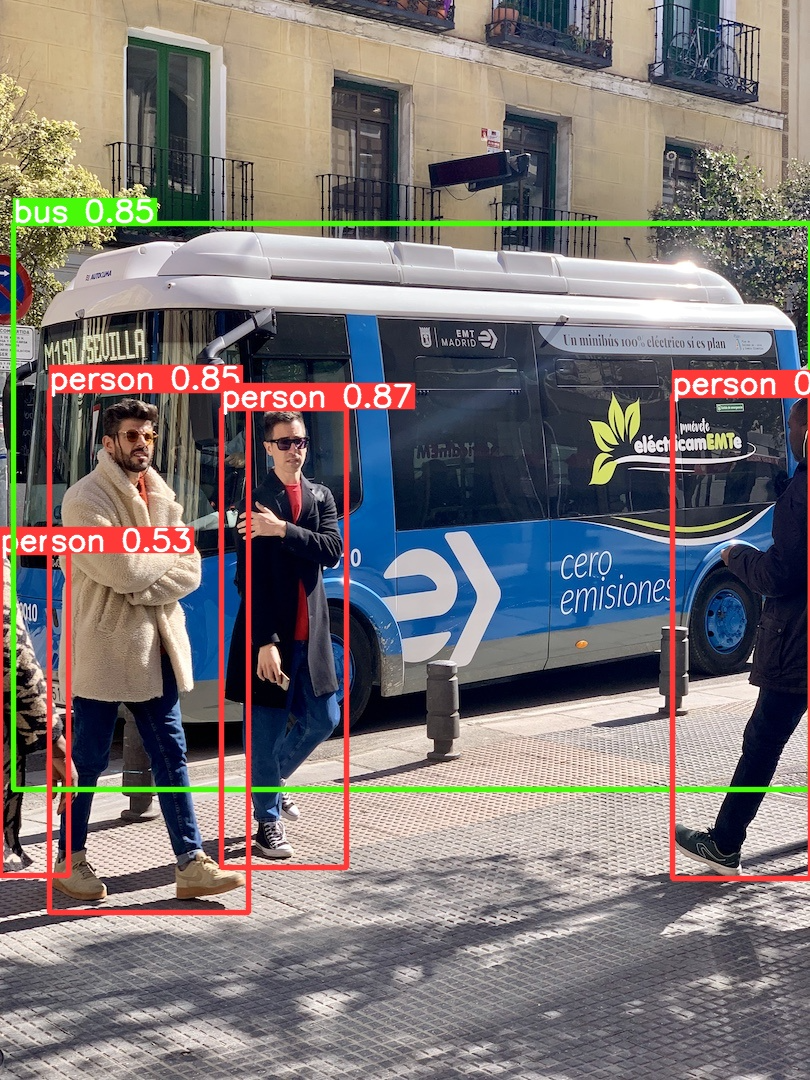
样例图zidane.jpg:

参数
该部分位于detect.py文件中:

关键参数
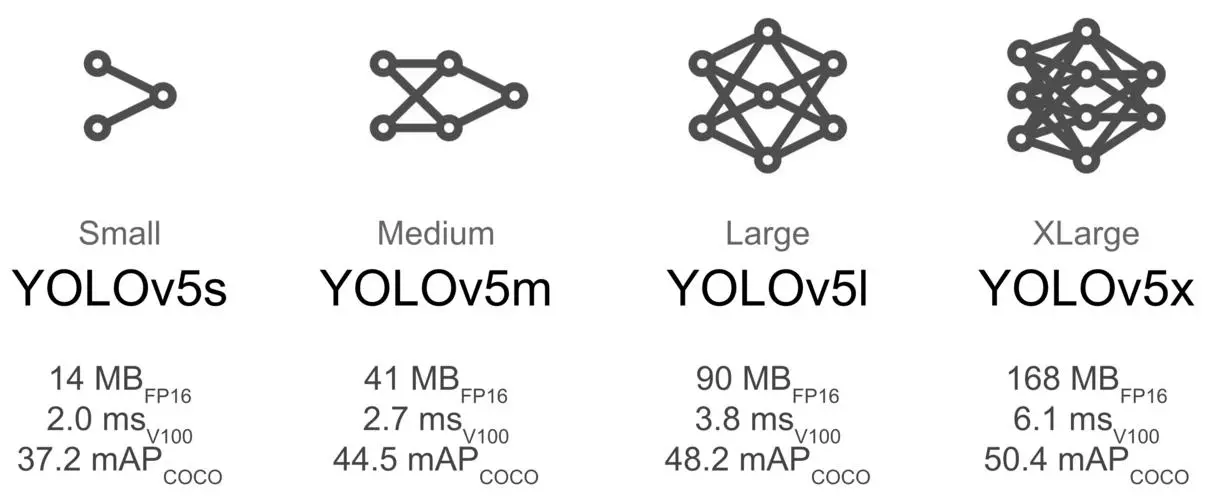
- weights:权重文件(训练好的模型文件),default为
yolov5s.pt,模型越大,精度越高,运算速度越慢- yolov5s.pt 小型模型
- yolov5m.pt 中型模型
- yolov5l.pt 大型模型
- yolov5x.pt 超大型模型
- source:检测目标,可以是单张图片、文件夹、屏幕或者摄像头等。
- conf-thres:置信度阈值,越低框越多,越高框越少。default为0.25,大于default都会进行标记
- iou-thres:IOU阈值,越低框越少,越高框越多。default默认为0.45,过大容易一个物体会被识别出多个框,过小则识别不出物体
- save-txt:把检测的目标的坐标文件输出为txt文件。
推理检测
知道上述参数之后,我们该如何使用自己想要的参数去训练模型呢?
打开终端——输入 python detect.py --参数 value,
如下将模型文件换成了yolov5m.pt
1 | python detect.py --weights yolov5m.pt |
初次训练自动下载yolov5m.pt文件。
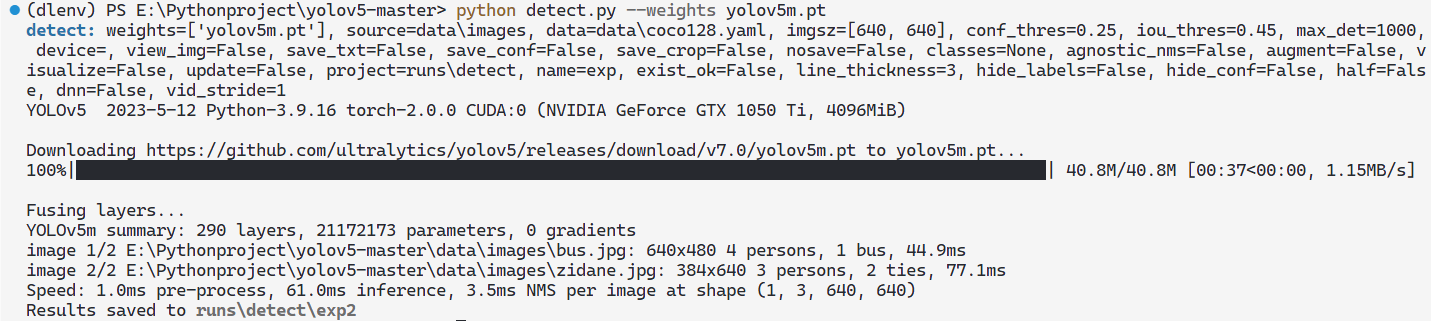
训练完成后查看结果,注意与之前的yolov5s模型训练结果对比:

如果想推理其他图片,可以将想检测的放入项目文件夹data/images中,
我从网络上下载了一张狂飙电视剧剧照,然后测试
1 | python detect.py --weights yolov5m.pt --source data/images/狂飙.jpg |

检测效果如下:

检测当前屏幕中存在的对象:
1 | python detect.py --weights yolov5m.pt --source screen |
推理结果会输出一段加速的视频,效果如下:
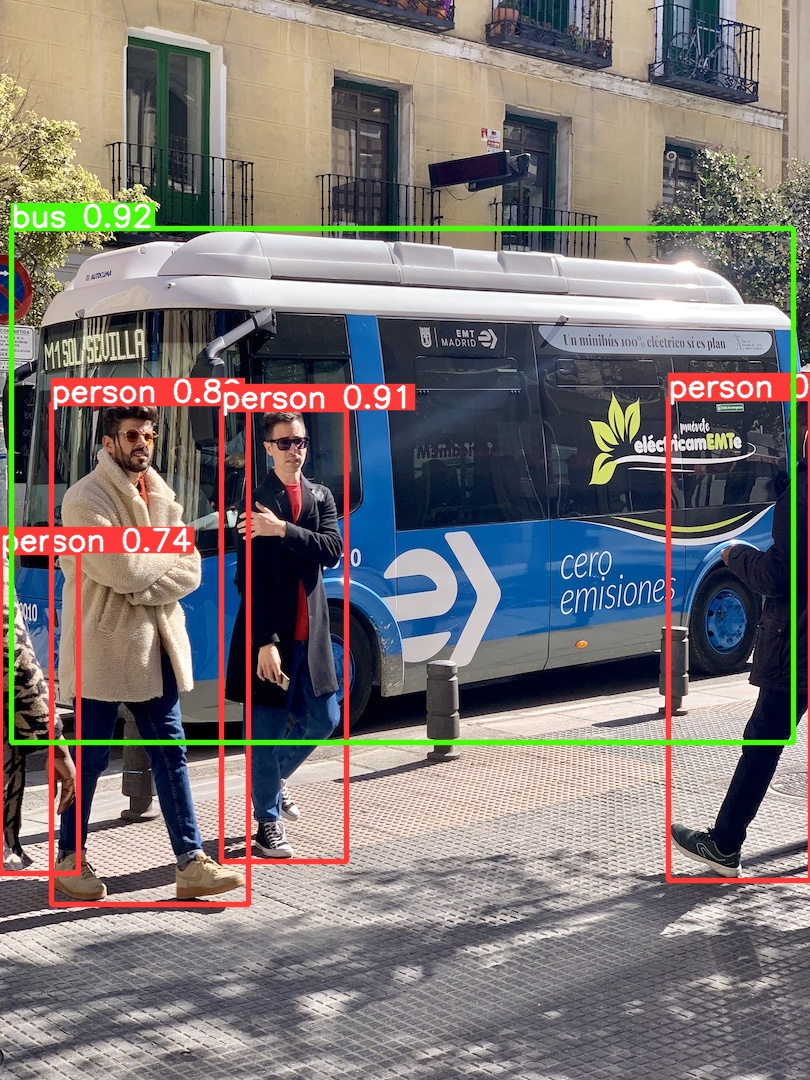
更改置信度阈值的话会发生什么呢?
输入命令,将置信度改为0.05:
1 | python detect.py --weights yolov5m.pt --source data/images/bus.jpg --conf-thres 0.05 |
检测效果如下,可以看到原来的bus.jpg图片中检测到了比之前更多的对象,
如果更改同样的IOU阈值呢?
输入命令,将IOU阈值调成0.05,
1 | python detect.py --weights yolov5m.pt --source data/images/bus.jpg --iou-thres 0.05 |
检测结果如下,框减少:
基于torch.hub的检测方法
可以直接运行py文件,而不需要终端手动输入命令执行了。
1 | import torch |
YOLOv5构建自定义数据集
准备工作
数据收集
图片类型数据
视频类型数据
使用opencv进行视频抽帧
将一段完整视频抽成多个一帧一帧的图片,以下利用死神VS火影(带土:卡卡西)的一段游戏视频演示:
原视频:NSUNS4带土VS鸣人
目录结构:

新建一个jupyter Notebook,命名extract.ipynb,导入opencv模块与matplotlib模块
1
2import cv2
import matplotlib.pyplot as pltret返回类型为bool类型,如果读取到了视频,就会返回true;未读取到,返回false。frame返回一帧图片
1
2
3
4
5#打开视频文件
video = cv2.VideoCapture('./BVN.mp4')
#读取一帧
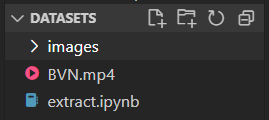
ret,frame = video.read()使用
plt.imshow(frame)显示读取到帧图片,注意这样显示的图片与原视频颜色不一致,是因为输出颜色为BGR格式切换到原来颜色可以使用
plt.imshow(cv2.cvtColor(frame,cv2.COLOR_BGR2RGB)),BGR转换RGB格式上述是将第一帧图片显示,如果想对整个视频的每帧图片进行读取并保存,需要怎么做呢?
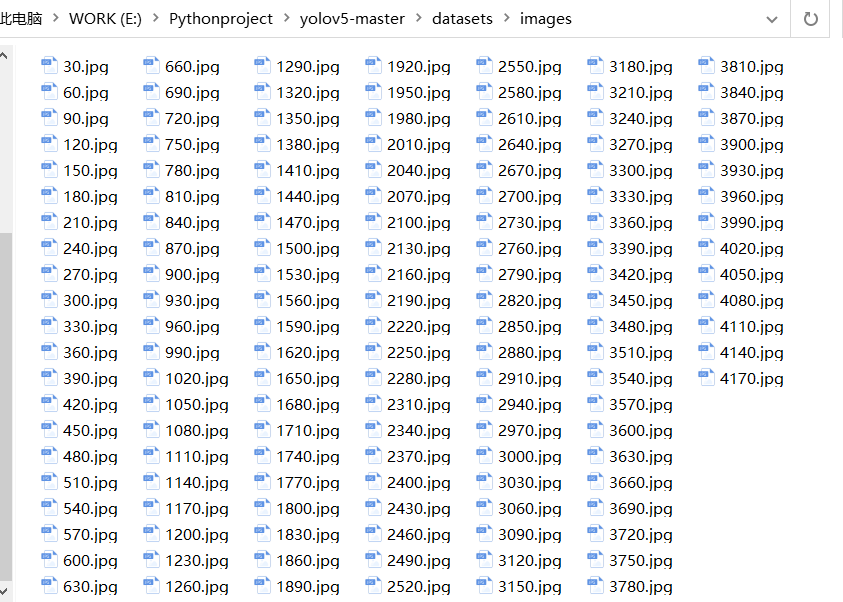
以下程序是捕获视频——对视频循环读取——每30帧输出一张图片(一个视频总帧数太多,全部图片会特别多)——将图片按格式写入images文件夹中。
1
2
3
4
5
6
7
8
9
10video = cv2.VideoCapture('./BVN.mp4')
num = 0 #计数器
save_step = 30 #间隔帧
while True:
ret,frame = video.read()
if not ret:
break
num += 1
if num % save_step == 0:
cv2.imwrite('./images/'+str(num)+'.jpg',frame)结果如下:

标注工具
labelimg
安装命令:
pip install labelimg终端输入
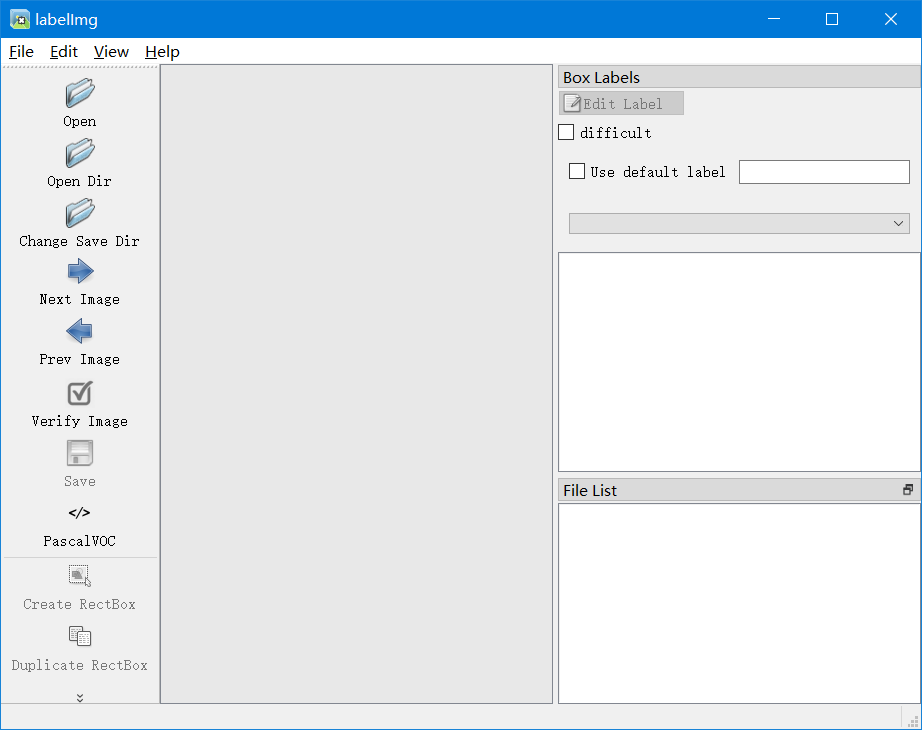
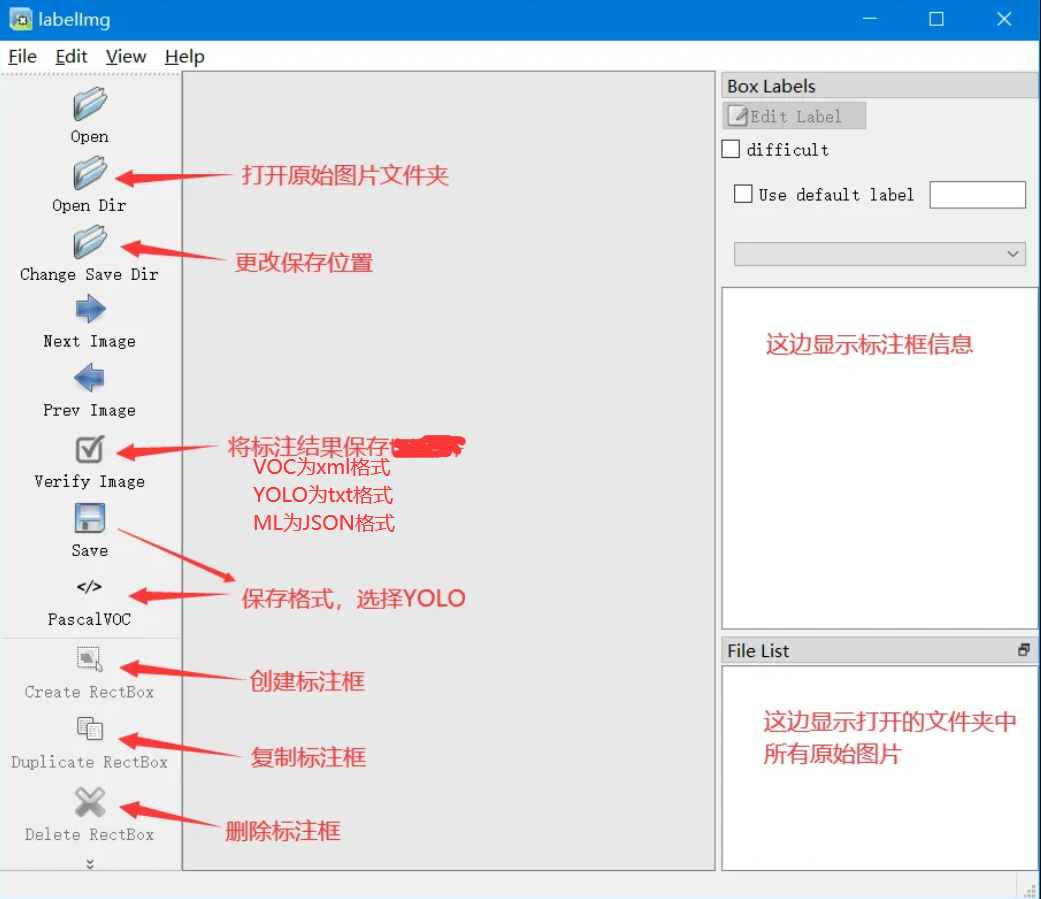
labelimg,打开labelimg:界面介绍:
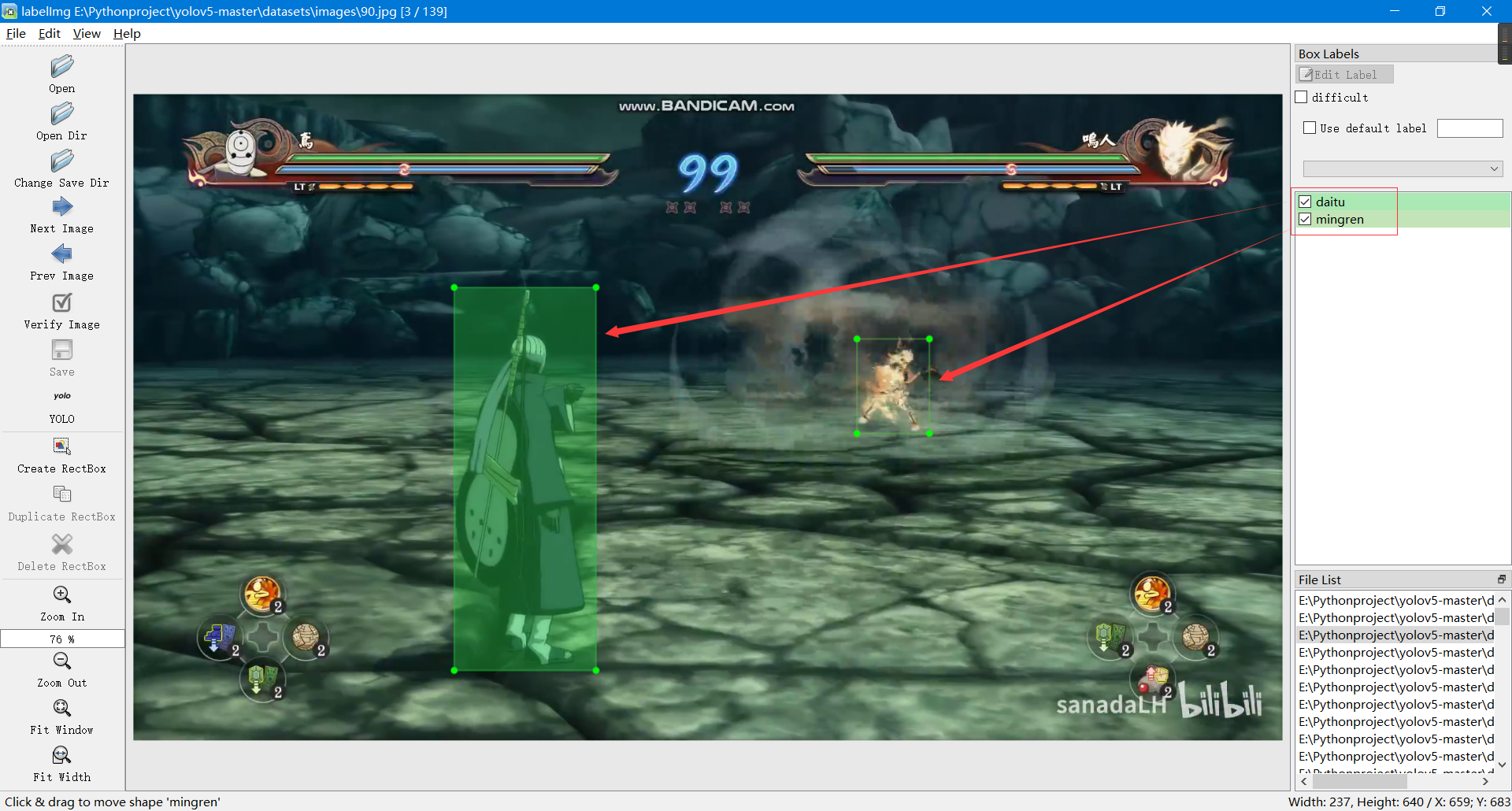
导入图片后进行标注(注意如果标注框一直强制正方形,请按快捷键 CTRL+SHIFT+R 或 点击‘Edit’->‘Draw Squares’ ):
结果保存到了labels文件夹中:
YOLOv5训练自定义数据集
数据调整
- images:存放图片
- train:训练集图片
- val:验证集图片
- labels:存放标签
- train:训练集标签文件,要与训练集图片名称一一对应
- val:验证集标签文件,要与验证集图片名称一一对应
classes.txt要从labels文件夹移到datasets文件夹下,然后images和labels分别划分训练集(多)、验证集(少),两文件夹的内容应当对应。
目录结构:
关键参数
- weights:预训练的权重文件
- data:数据集描述文件
训练模型
在data文件夹下创建bvn.yaml配置文件,规定对应标签。
1 | # Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..] |
打开train.py文件,修改参数–data为’data/bvn.yaml’
点击运行即可训练。
默认是训练100epoch,慢慢等
最后训练好的结果会保存到runs/train中。
打开detect.py文件,输入命令
1 | python detect.py --weights runs/train/exp2/weights/best.pt --source datasets/BVN.mp4 --view-img |
这样会边推理边播放视频,播放完后视频生成。
检测效果视频如下:
YOLOv5利用PyQT5实现可视化界面
环境搭建
- Pyside6安装:pip install pyside6
- pyside6 designer:打开
<虚拟环境位置>\Lib\site-packages\PySide6 - Qt for Vscode:Vscode扩展
实现过程
打开PySide6的designer.exe,对图形界面设计。
以下是我绘制的GUI,具体元素如图:
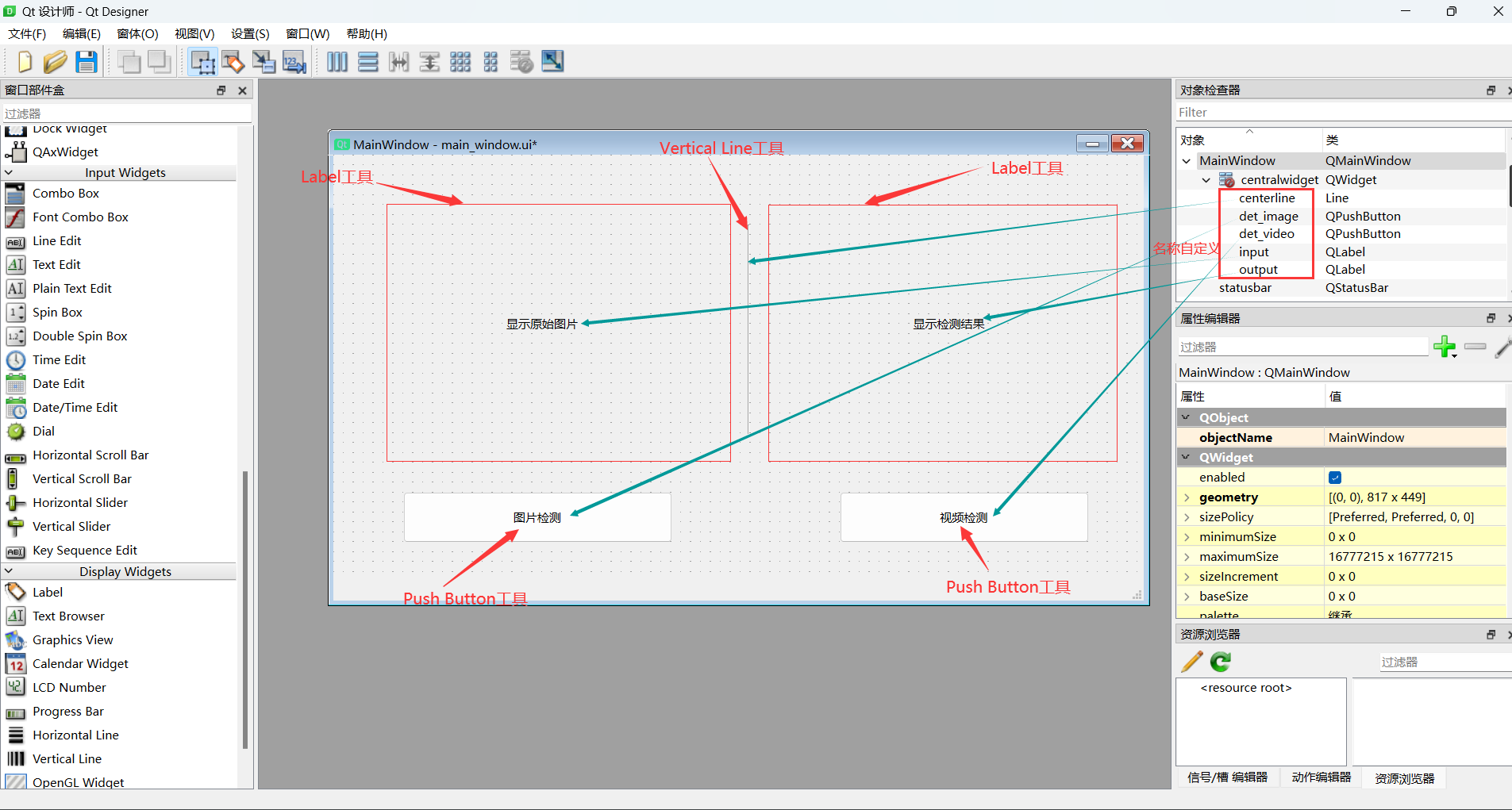
其中Label工具属性设置如下:
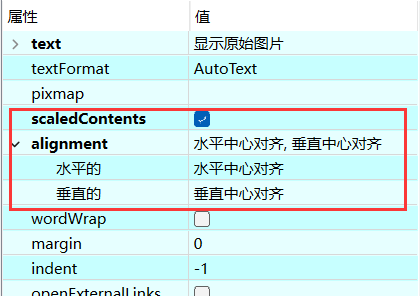
按Ctrl+S将图形界面保存,文件名为main_windows.ui,其实它就是一个标准XML格式的文本文件。
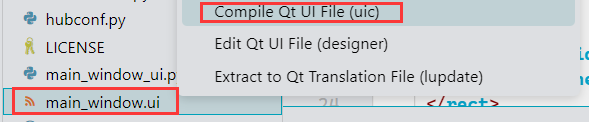
为了将它做成后续的检测界面,需要用Qt for Vscode插件对ui文件转换,如下:
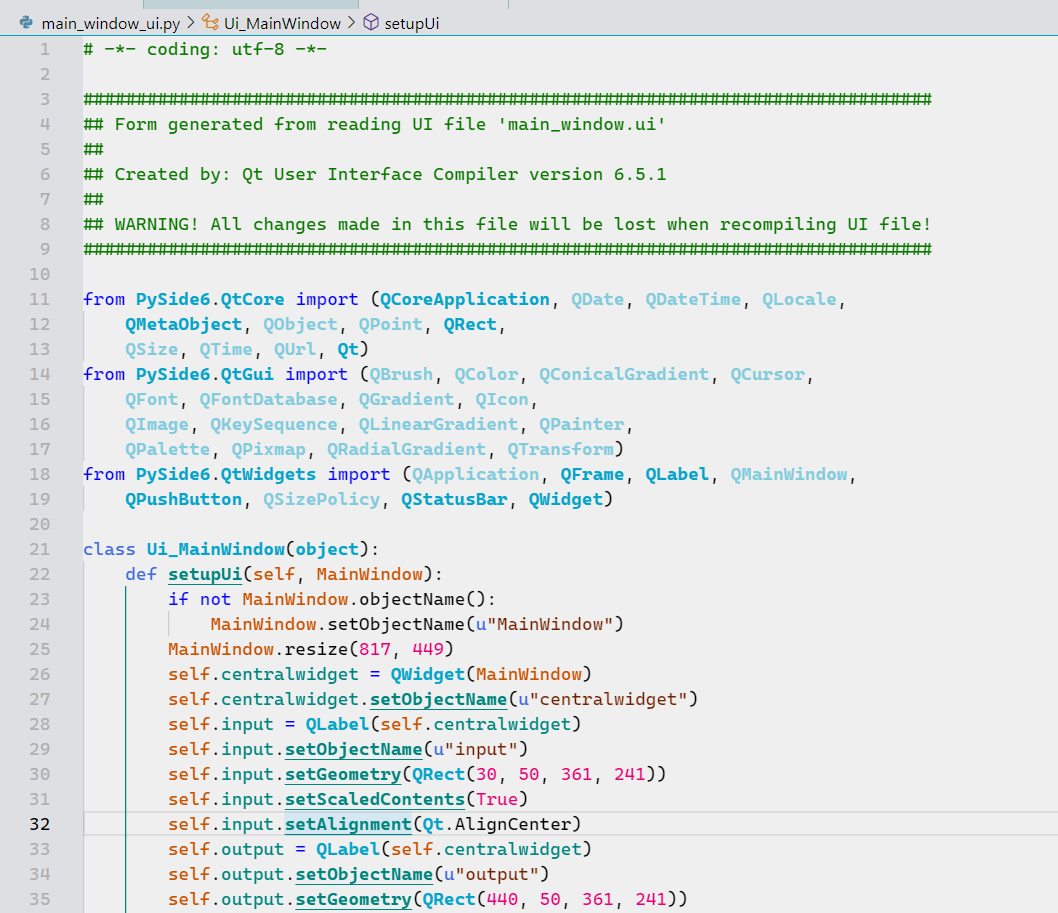
上述转换为一个名为main_window_ui.py的文件,里面有个Ui_MainWindow类,一会儿我们会用到,如图所示:
新建一个base_ui.py用于写GUI主程序,
用到了前面的基于torch.hub方法,用模型是本文开始的自定义数据集训练的best.pt模型文件。
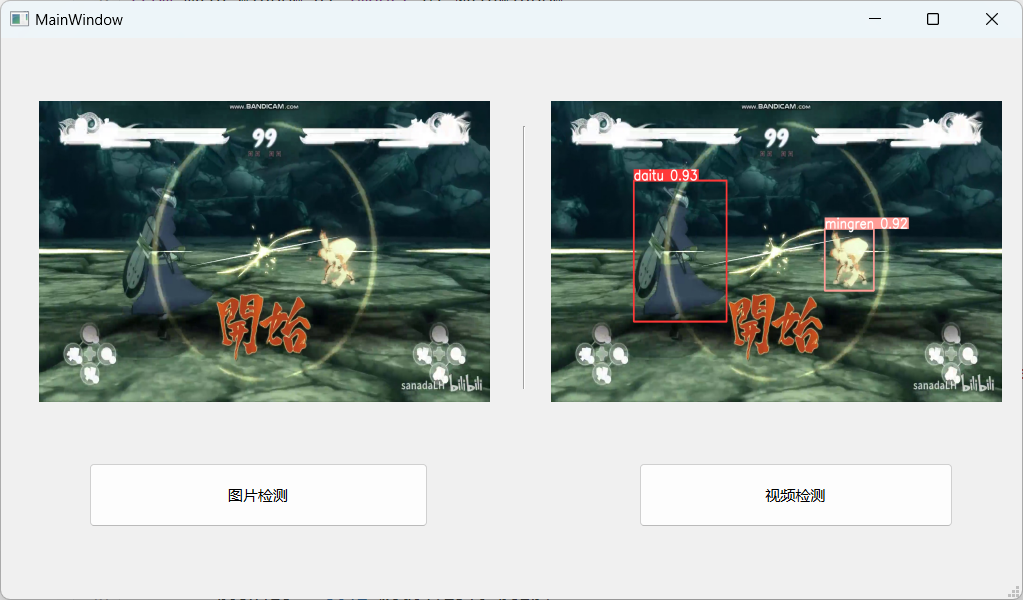
整体分为图片检测与视频检测两部分。
原理为:
- (图片)点击按钮,打开文件路径,选中图片打开后,执行image_pred函数,将检测结果以图像形式显示出来。
- (视频)点击按钮,打开文件路径,选中视频打开后,执行video_pred函数,对原视频按一定时间间隔抽帧并对每帧图片检测,最后将所有帧的检测结果连续地显示出来。
代码如下:
1 | import cv2 |
效果
功能上基本满足,界面适应性上还有点问题,无法自动适配任意大小,
YOLOv5利用Gradio搭建Web GUI

Gradio是一个机器学习模型可视化的Python库,简单来说Gradio可以通过python生成一套html页面,其中包含大部分组件,通过设置相关组件可以实现丰富的交互功能,让机器学习模型拥有用户友好的图形界面。

Gradio与Hugging Face合作密切,很多机器学习爱好者与研究员常常会将gradio的模型部署到 HuggingFace的 Space托管空间中,实现外界免费访问
Gradio常用于测试AI模型的效果,如图像识别,姿态估计,图像分割。在将训练完成的模型加载之后,可以对测试数据集进行实时检测。
Gradio的主要优点包括:
简单易用,只需要几行代码就可以创建界面。无需前端开发经验。
支持丰富的交互组件,如滑块、单选框、文本框等。可以快速构建复杂的界面。
可以为TensorFlow、PyTorch等多种框架的模型构建界面。
支持在线部署。可以通过链接与他人分享你的模型。
支持在Jupyter Notebook中嵌入组件,使Notebook更加交互式。
开源免费。社区活跃,文档丰富。
Gradio官方网站:www.gradio.app ,参考文档:Gradio — 文档 官方Github:gradio-app/gradio:构建和分享令人愉快的机器学习应用程序
该部分是基于Gradio来搭建YoLov5模型的WebUI系统,分别实现本地与外网访问,所用模型为上述火影忍者训练集训练好的模型。如果想实现特定的人或物的检测,可以更换其他模型。
-
- 操作如下:
如果环境中没有Gradio库的话,需要先行安装,
1
pip install gradio
创建Gradio_demo.py文件用于编写WebUI程序
示例代码:
1 | import torch |
效果图:
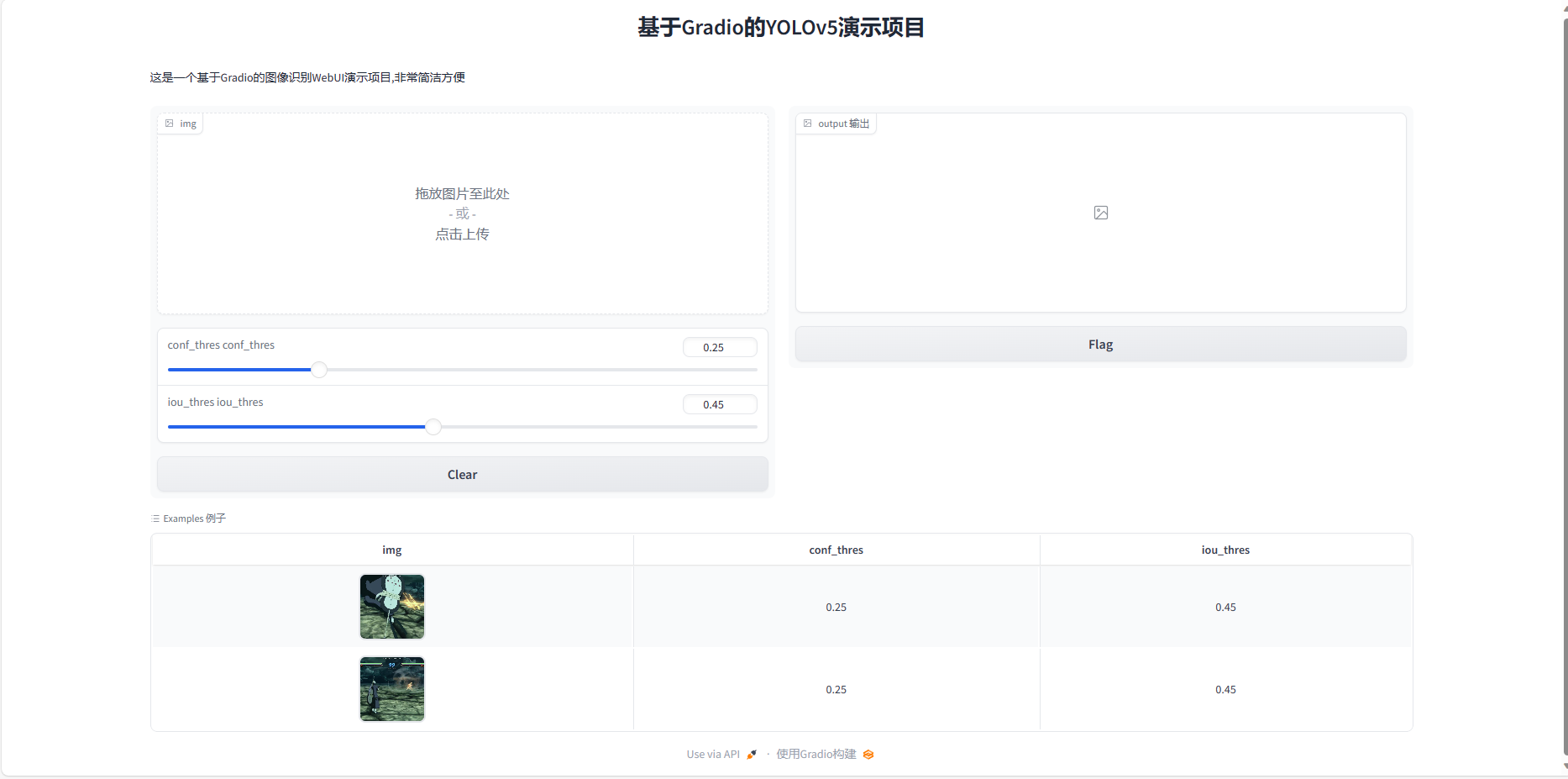
VSCode与AutoDL服务器连接
进行深度学习模型训练时,常常需要用到GPU进行加速,但是由于自己用的电脑GPU算力较低,所以跑模型一般常借助GPU服务器来帮助训练,以下是使用VSCode和AutoDL(服务器提供商)来完成在服务器上的模型训练。
打开VScode插件
- 安装Remote-SSH远程连接插件
打开远程连接窗口
- 在VScode左下角
连接服务器
- 连接主机
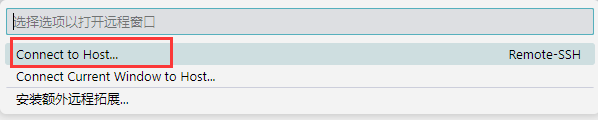
- 添加新的服务器

- 这个地方输入登陆指令,我开的服务器是
ssh -p 44599 [email protected]


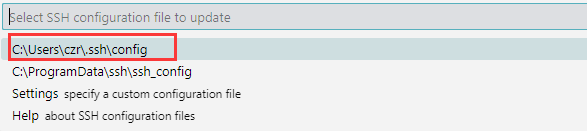
- 这个地方默认选择第一个,会将SSH configuration存到本地。
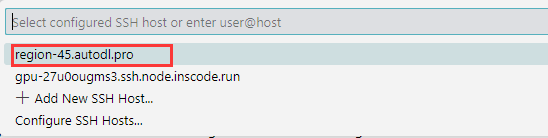
- 然后这时候重新打开运程连接工具,新加的服务器链接就有了。这时候点击新加的这个。
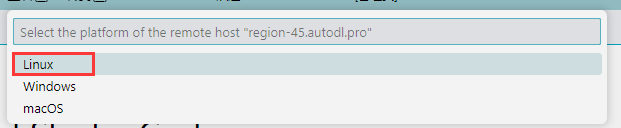
- 选择服务器的操作系统
- 输入服务器密码

使用服务器
- 这时打开文件夹,这显示的便是服务器中的文件。
- 再打开一个项目测试时,可能会出现
安装Python扩展提示,因为之前的Python扩展是安装在本地,在服务器使用VScode,需要重新安装扩展。
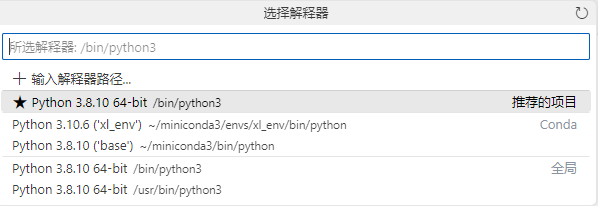
- 运行需要选择一个解释器,服务器中有多个,其中Base为Anaconda默认的,另一个为深度学习专用虚拟环境
- 标题: 深度学习记录(四):YOLOv5 7.0实战
- 作者: 狮子阿儒
- 创建于 : 2023-05-13 22:29:26
- 更新于 : 2024-03-03 21:31:26
- 链接: https://c200108.github.io/blog/2023/05/13/深度学习记录(四):YOLOv5 7.0实战/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。