

大数据处理与实践(1)——Hadoop

前言
Hadoop是什么?
Hadoop是一个由Apache基金会所开发的分布式系统基础架构, 它主要解决海量数据存储与计算的问题,为大数据的分布式存储与处理提供了一个软件框架,是大数据技术中的基石。
Apache Hadoop的核心模块分为存储和计算模块,前者被称为Hadoop分布式文件系统(HDFS),后者即MapReduce计算模型。
Apache Hadoop框架由以下基本模块构成:
- Hadoop Common – 包含了其他Hadoop 模块所需的库和实用程序;
- Hadoop Distributed File System (HDFS) – 一种将数据存储在集群中多个节点中的分布式文件系统,能够提供很高的带宽;
- Hadoop YARN – (于2012年引入) 一个负责管理集群中计算资源,并实现用户程序调度的平台
- Hadoop MapReduce – 用于大规模数据处理的MapReduce计算模型实现;
- Hadoop Ozone – (于2020年引入) Hadoop的对象存储。
功能
1、海量数据存储
2、资源管理,调度和分配
HDFS框架
HDFS是Master和Slave的主从结构。主要由NameNode、Secondary NameNode、DataNode构成。
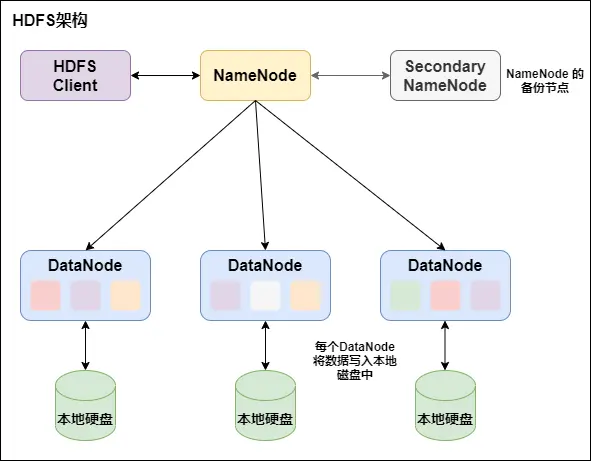
NameNode:负责管理整个文件系统的元数据,以及每一个路径(文件)所对应的数据块信息。
如果NameNode挂掉了,文件就会无法重组,怎么办?有哪些容错机制?Hadoop可以配置成HA即高可用集群,集群中有两个NameNode节点,一台active主节点,另一台stan-dby备用节点,两者数据时刻保持一致。当主节点不可用时,备用节点马上自动切换,用户感知不到,避免了NameNode的单点问题。
Secondary NameNode:用来监控 HDFS 状态的辅助后台程序,每隔一段时间获取 HDFS 元数据的快照。最主要作用是辅助 NameNode 管理元数据信息。紧急情况下可辅助恢复NameNode。
DataNode:Slave节点,实际存储数据、执行数据块的读写并汇报存储信息给NameNode。
HDFS特性
对于HDFS的作用可以用以下例子来解释:
举例1:一名用户想要获取某个路径的数据,而数据存放在很多机器上,拥有Hadoop就不需要考虑数据在哪个机器上,HDFS会自动搞定
举例2:如果一个100p的文件,希望过滤出含有Hadoop字符串的行。这种场景下,HDFS分布式存储,突破了服务器硬盘大小的限制,解决了单台机器无法存储大文件的问题,同时MapReduce分布式计算可以将大数据量的作业先分片计算,最后汇总输出。
- 1. master/slave 架构(主从架构)
HDFS 采用 master/slave 架构。一般一个 HDFS 集群是有一个 Namenode 和一定数目的 Datanode 组成。Namenode 是 HDFS 集群主节点,Datanode 是 HDFS 集群从节点,两种角色各司其职,共同协调完成分布式的文件存储服务。
- 2. 分块存储
HDFS 中的文件在物理上是分块存储(block)的,块的大小可以通过配置参数来规定,默认大小在 hadoop2.x 版本中是 128M。
- 3. 名字空间(NameSpace)
HDFS 支持传统的层次型文件组织结构。用户或者应用程序可以创建目录,然后将文件保存在这些目录里。文件系统名字空间的层次结构和大多数现有的文件系统类似:用户可以创建、删除、移动或重命名文件。
Namenode 负责维护文件系统的名字空间,任何对文件系统名字空间或属性的修改都将被 Namenode 记录下来。
HDFS 会给客户端提供一个统一的抽象目录树,客户端通过路径来访问文件,形如:hdfs://namenode:port/dir-a/dir-b/dir-c/file.data。
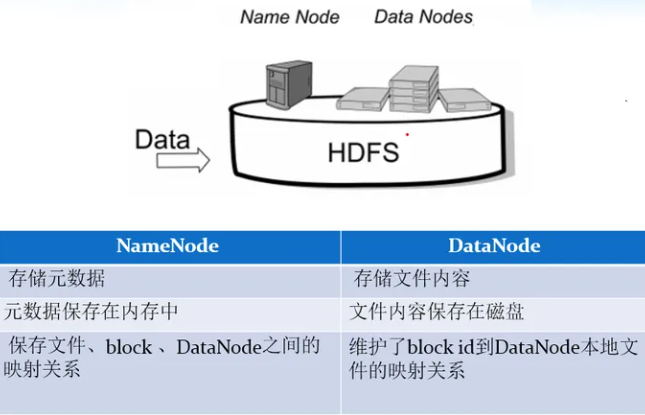
- 4. NameNode 元数据管理
我们把目录结构及文件分块位置信息叫做元数据。NameNode 负责维护整个 HDFS 文件系统的目录树结构,以及每一个文件所对应的 block 块信息(block 的 id,及所在的 DataNode 服务器)。
- 5. DataNode 数据存储
文件的各个 block 的具体存储管理由 DataNode 节点承担。每一个 block 都可以在多个 DataNode 上。DataNode 需要定时向 NameNode 汇报自己持有的 block 信息。 存储多个副本(副本数量也可以通过参数设置 dfs.replication,默认是 3)
- 6. 副本机制
为了容错,文件的所有 block 都会有副本。每个文件的 block 大小和副本系数都是可配置的。应用程序可以指定某个文件的副本数目。副本系数可以在文件创建的时候指定,也可以在之后改变。
- 7. 一次写入,多次读出
HDFS 是设计成适应一次写入,多次读出的场景,且不支持文件的修改。
正因为如此,HDFS 适合用来做大数据分析的底层存储服务,并不适合用来做网盘等应用,因为修改不方便,延迟大,网络开销大,成本太高。
HDFS操作
由于本笔记是基于Docker部署的Hadoop大数据集群,使用云桌面实验环境与大数据集群相联动,因而如何搭建Hadoop集群等等操作便不再演示🥲
完整命令概述
1 | hadoop fs [generic options] [-appendToFile <localsrc> ... <dst>] |
常用命令
初始
连接集群节点
1 | ssh 节点名 |
查看当前集群配置
1 | cat /etc/hosts |
准备
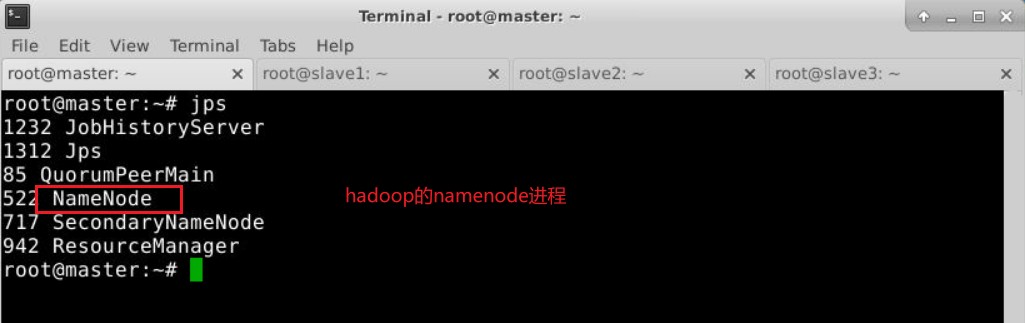
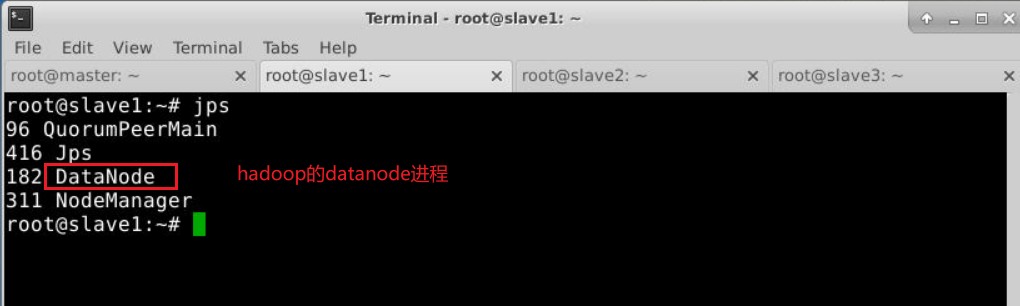
开启hadoop大数据服务,在master节点下操作
1 | bash /scripts/hadoop/start-hadoop.sh |
验证是否开启:
创建工作目录
1 | #先从master节点退回桌面 |
操作
查看目录
1 | hadoop fs -ls 目录名 |
执行效果:

创建目录
1 | hadoop fs -mkdir 目录名 |
执行效果:


删除目录
1 | hadoop fs -rm -r 目录名 |
执行效果:

文件上传
1 | hadoop fs -put 本地文件路径 HDFS文件路径 |
执行效果:

文件下载
1 | hadoop fs -get HDFS文件路径 本地文件路径 |
执行效果:
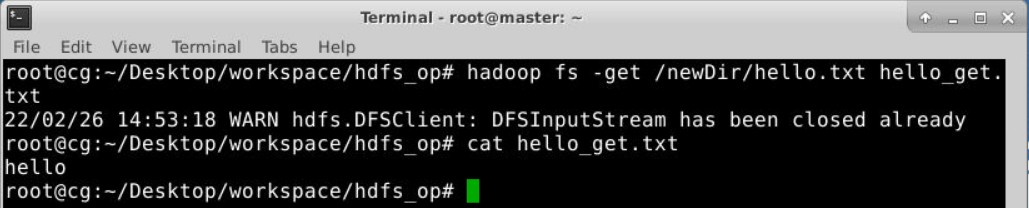
查看文件内容
1 | hadoop fs -cat 文件路径 |
执行效果:

查看文件大小
1 | hadoop fs -du 参数 目录或文件 |
执行效果:

复制文件
1 | hadoop fs -cp 文件名 复制后的文件名 |
执行效果:

重命名/移动文件
1 | hadoop fs -mv 目录或文件 目录 |

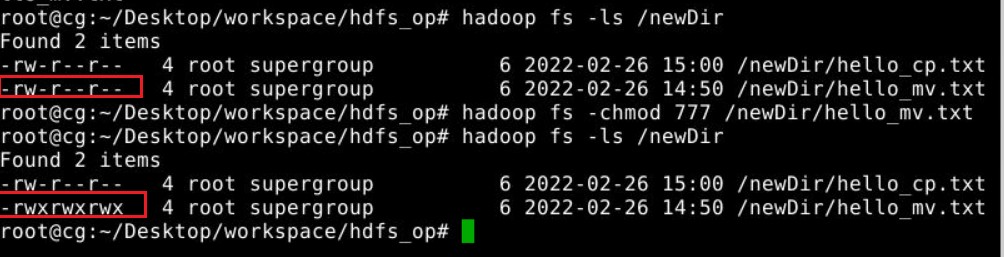
文件权限修改
1 | hadoop fs -chmod 权限选项 目录或者文件 |
权限选项有哪些?
-rw——- (600) 只有拥有者有读写权限。
-rw-r–r– (644) 只有拥有者有读写权限;而属组用户和其他用户只有读权限。
-rwx—— (700) 只有拥有者有读、写、执行权限。
-rwxr-xr-x (755) 拥有者有读、写、执行权限;而属组用户和其他用户只有读、执行权限。
-rwx–x–x (711) 拥有者有读、写、执行权限;而属组用户和其他用户只有执行权限。
-rw-rw-rw- (666) 所有用户都有文件读、写权限。
-rwxrwxrwx (777) 所有用户都有读、写、执行权限。
执行效果:
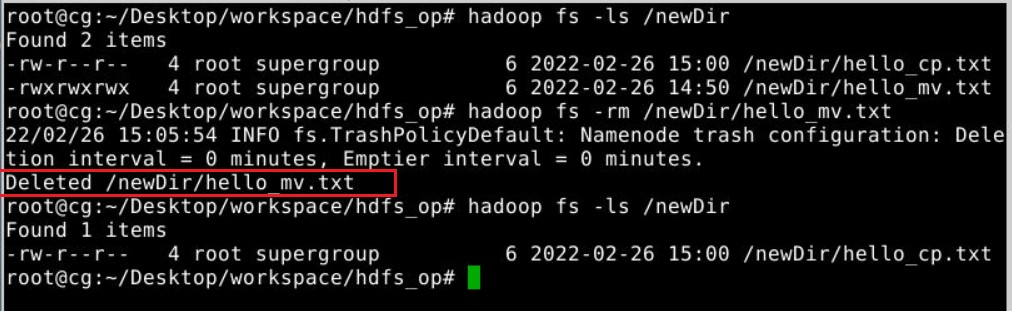
删除文件
1 | hadoop fs -rm 文件路径 |
执行效果:
查看文件系统信息
1 | hadoop fs -df -h |
执行效果:

HDFS编程
在进行HDFS编程前,需要开启Hadoop服务,操作HDFS操作的准备章节。
创建工作目录
因为本实验的工作目录为~/Desktop/workspace/hdfs_pro,所以需要创建并初始化目录
1 | root@cg:~/Desktop# mkdir -p ~/Desktop/workspace/hdfs_pro |
这样便创建完成——root@cg:~/Desktop/workspace/hdfs_pro
创建IDEA工程
启动IDEA环境。
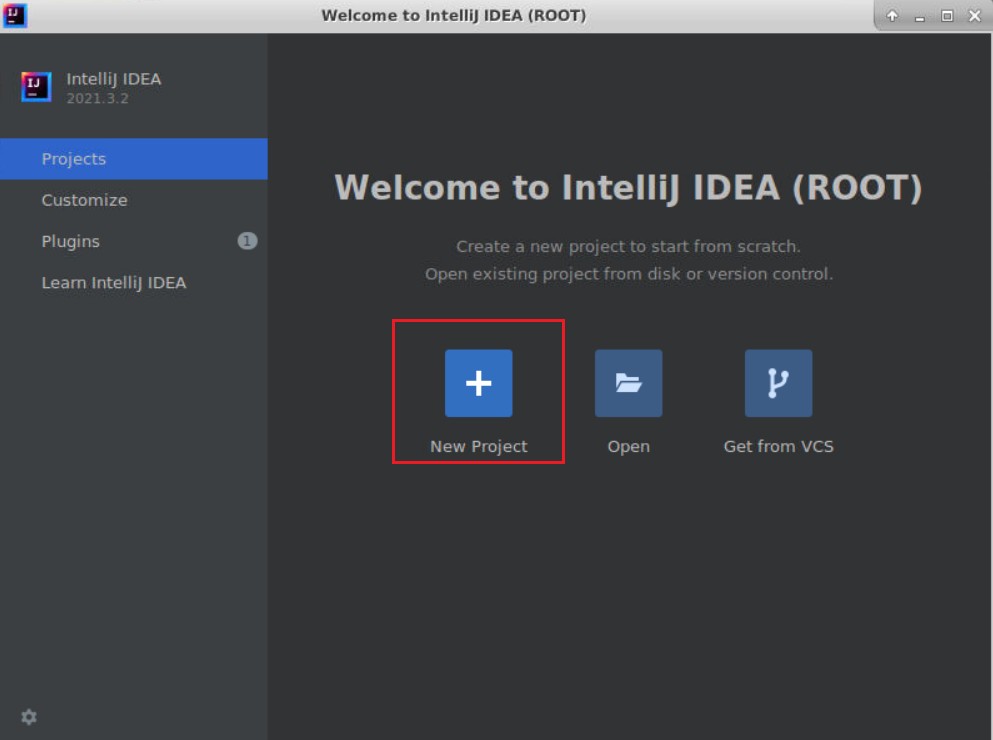
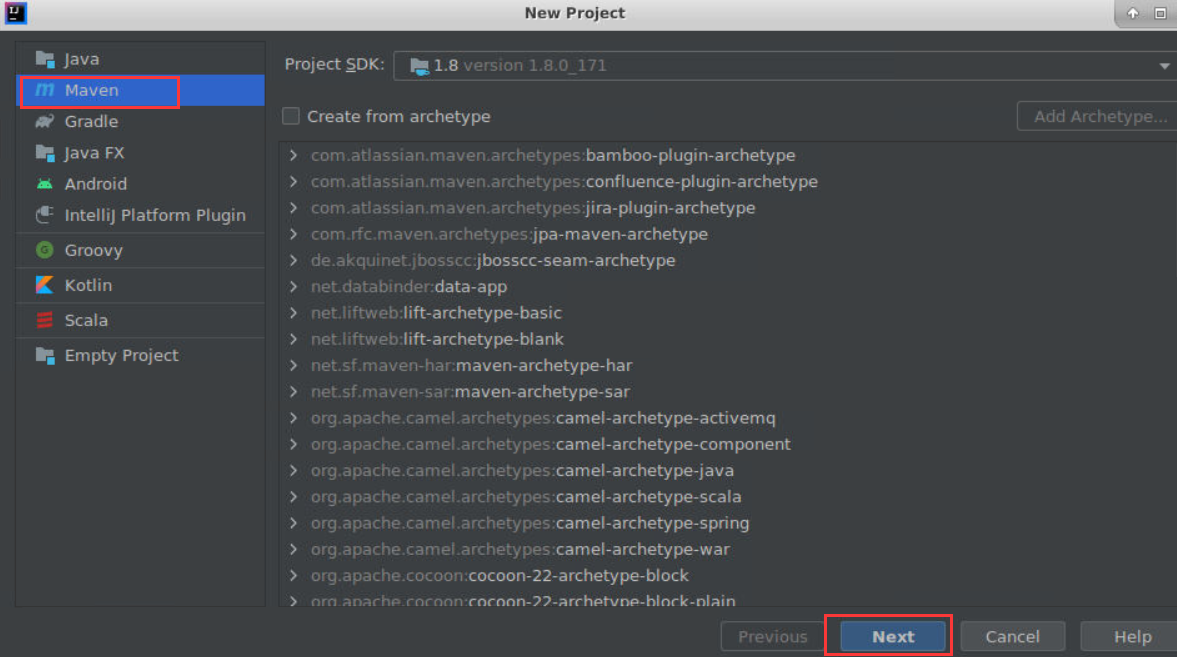
在项目名称(Project Name)处填入hdfs_pro,将工程位置选择为本实验的工作目录,再点击Finish。
如下图所示:
导入依赖
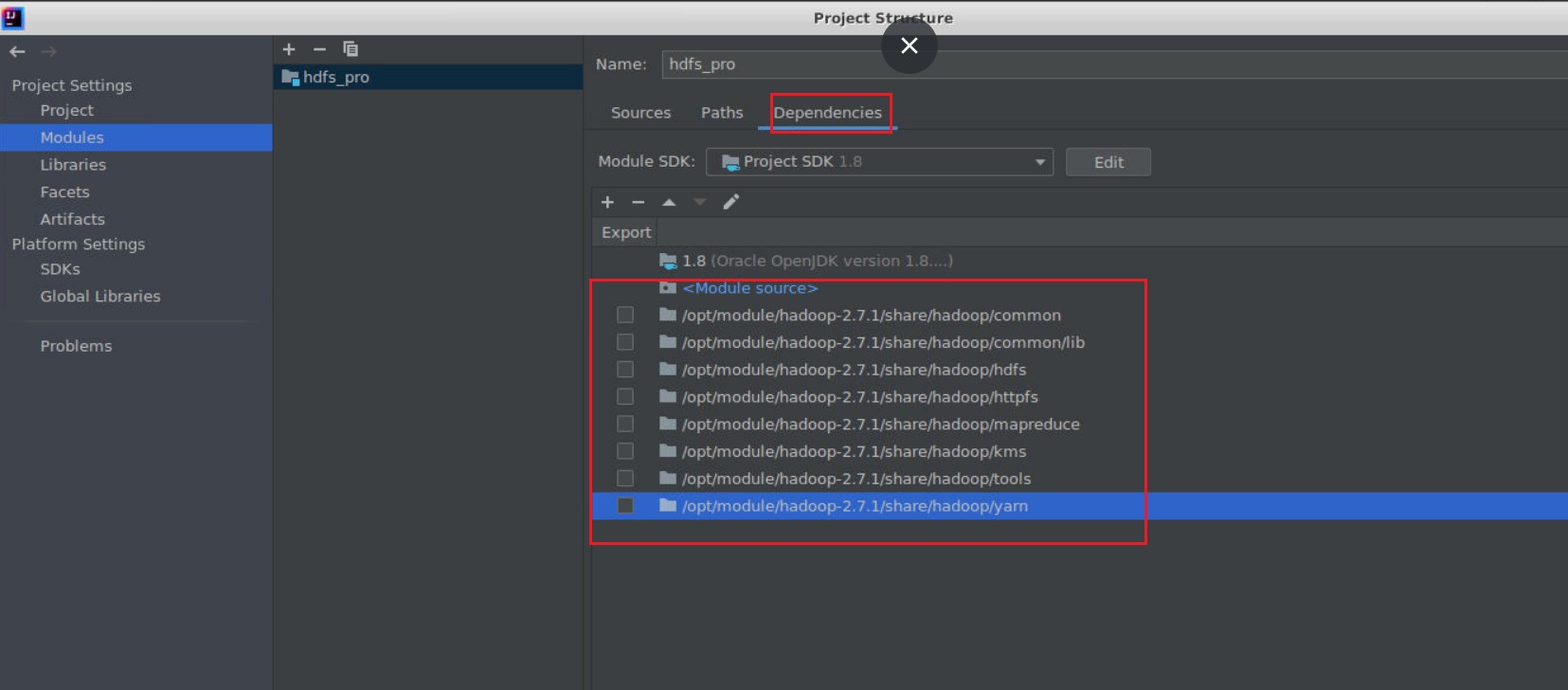
依次点击:File -> Project Structure...
Modules -> Dependencies, 点击**+**号添加 JARs or Directories...
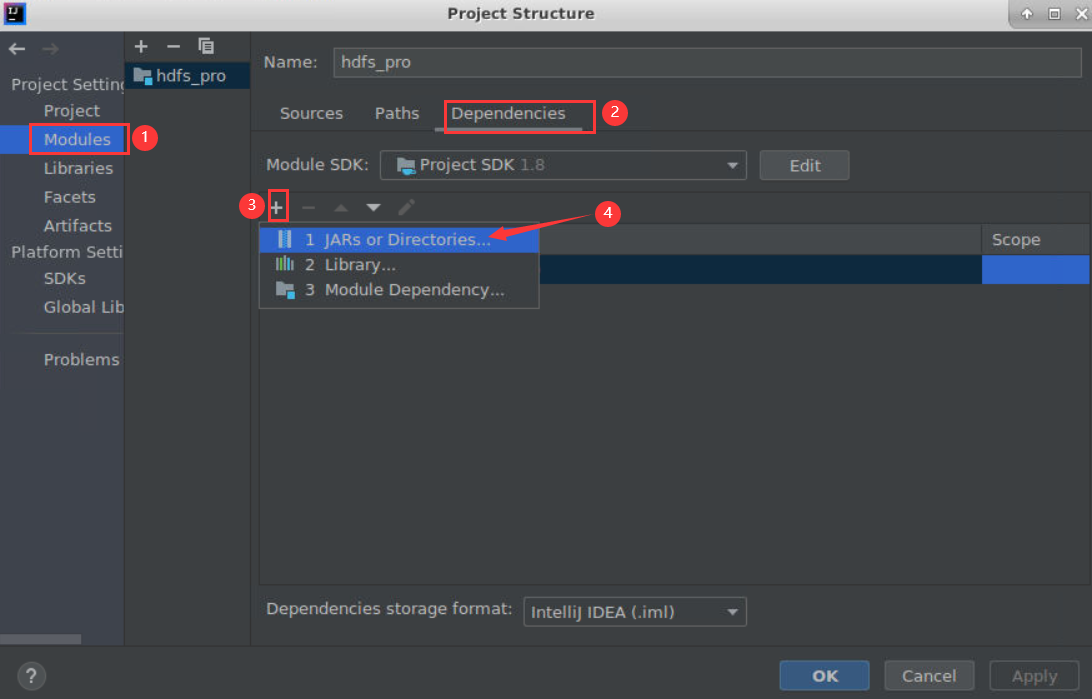
依次添加以下文件:
- /opt/module/hadoop-2.7.1/share/hadoop/common
- /opt/module/hadoop-2.7.1/share/hadoop/common/lib
- /opt/module/hadoop-2.7.1/share/hadoop/hdfs
- /opt/module/hadoop-2.7.1/share/hadoop/httpfs
- /opt/module/hadoop-2.7.1/share/hadoop/kms
- /opt/module/hadoop-2.7.1/share/hadoop/mapreduce
- /opt/module/hadoop-2.7.1/share/hadoop/tools
- /opt/module/hadoop-2.7.1/share/hadoop/yarn
目录的相关操作
创建目录
相关接口说明
创建目录可以使用FileSystem的mkdirs方法,该方法的含义如下:
- 函数原型:
public boolean mkdirs(Path f) throws IOException - 函数功能:调用该方法,根据f指定的路径创建目录。目录的权限为默认权限。
- 参数说明:
f,Path对象。表示要创建的目录的路径。 - 返回值:如果目录成功创建,返回
true。 - 异常:如果遇到IO故障,抛出
IOException异常。
mkdirs还有一个带有目录权限参数的版本,其原型为:
1 | public abstract boolean mkdirs(Path f, FsPermission permission) throws IOException |
完整实验代码
将 hdfs_pro 项目下 src/main/java 目录新建名为 CreateDir 的类
(选中java文件夹->File->new->Java Class->在name选项中填入 CreateDir->Finish)
该实验的完整实验代码如下:
1 | import org.apache.hadoop.conf.Configuration; |
将该代码拷贝到CreateDir.java文件中。如下图所示:
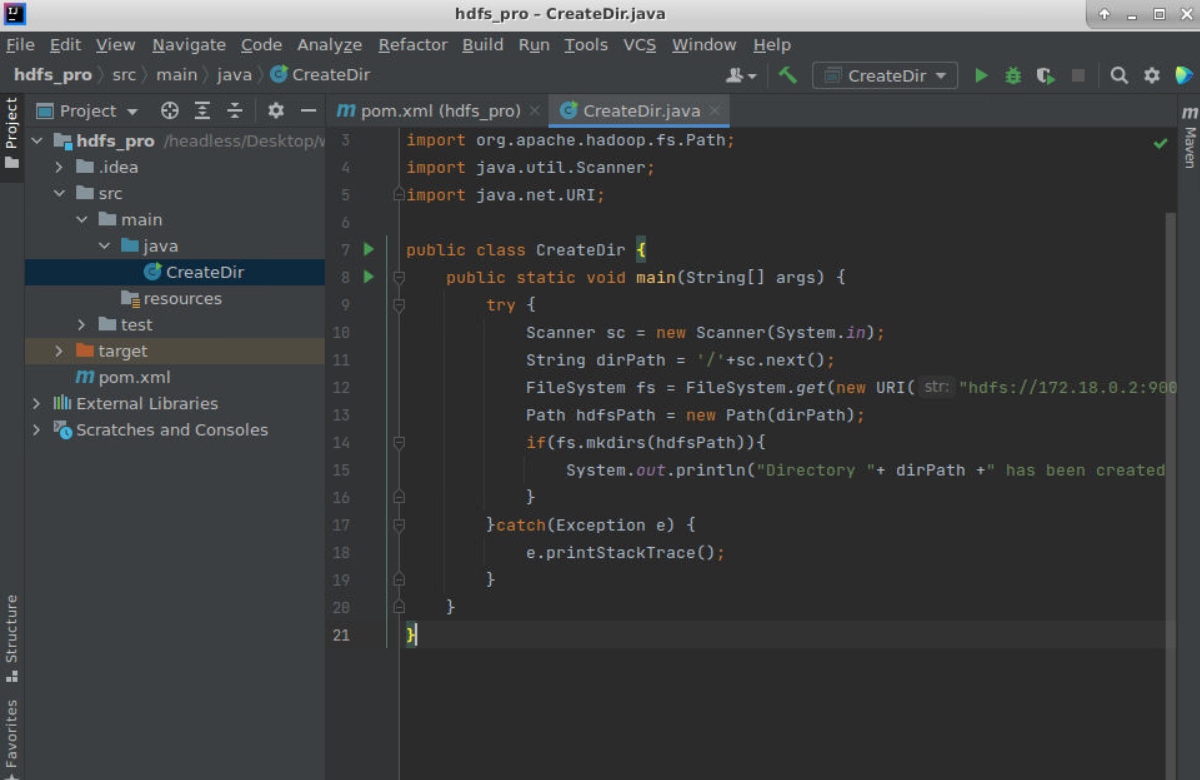
以上代码中主要调用fs的mkdirs方法来创建目录,如果目录创建成功,会输出相应提示信息。
运行结果分析
在CreateDir.java上,点击右键,选择Run ,执行程序。
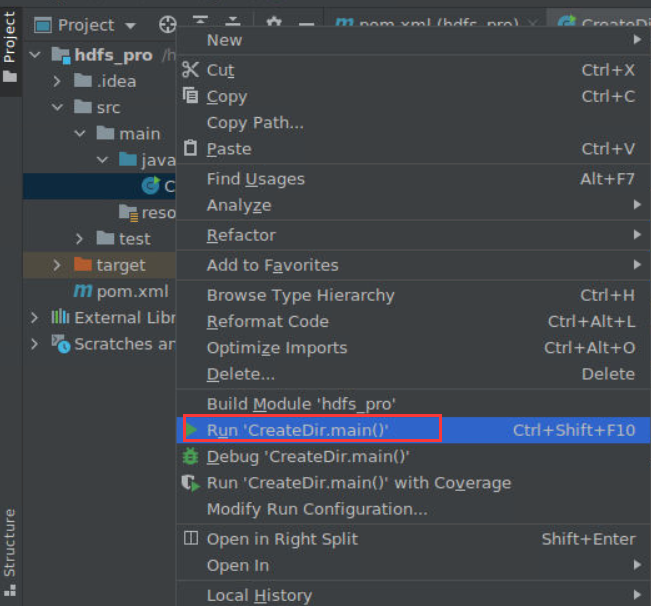
输入目录名newdir。
运行结果的截图如下:

如图所示,目录newDir 已经被成功创建。
目录存在性判断
相关接口说明
判断文件是否存在需要使用FileSystem的exists方法,该方法的详细含义如下:
方法名:exists
方法原型:public boolean exists(Path f) throws IOException
接口功能:检查某个路径所指的目录是否存在。
接口说明:参数f的含义为源路径。如果目录存在,返回值为true。如果IO故障会抛出IOException异常。
完整实验代码
将 hdfs_pro 项目下 src/main/java 目录新建名为 DirExist 的类
(选中java文件夹->File->new->Java Class->在name选项中填入DirExist->Finish)
该实验的完整代码如下所示:
1 | import org.apache.hadoop.conf.Configuration; |
运行结果分析
使用和上一节相同的方法运行该代码。
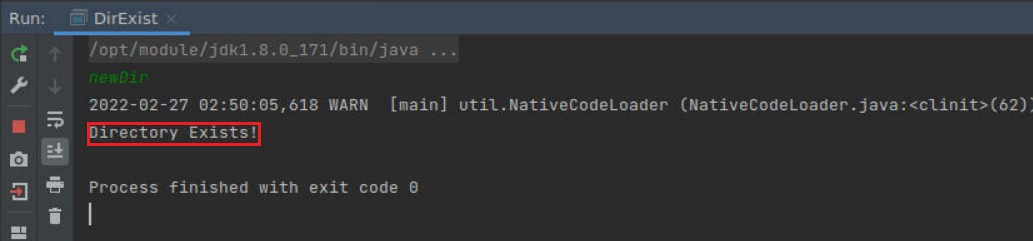
输入正确目录名:newDir
结果如下:
输入错误目录名:Newdir
结果如下:
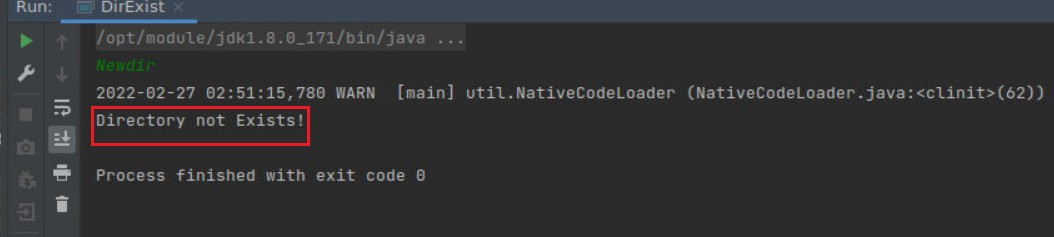
如图所示,程序判断无误。
列出目录中的内容
相关接口说明
在HDFS文件系统上浏览某个目录中子文件和子目录时,需要使用FileSystem类提供的listStatus方法,该方法将返回该目录下所有子文件和子目录的详细信息,包括文件的长度、块大小、备份数、修改时间、所有者以及权限等信息,这些信息都被封装在FileStatus对象中。调用listStatus方法时需要提供目录的路径,listStatus方法的详细说明如下:
函数原型:public abstract FileStatus[] listStatus(Path f) throws FileNotFoundException, IOException
函数功能:根据输入参数f所指定的目录,列出该目录下所有子文件/子目录的详细信息。注意,该接口不保证返回的文件/目录信息是有序的。
函数参数:f,指定目录的路径。
返回值:f所指定的目录下所有子文件/子目录的详细信息。
异常:两种异常,FileNotFoundException和IOException。当所指定的目录不存在时,抛出FileNotFoundException异常。当遇到IO故障时,返回IOException异常。
完整实验代码
将hdfs_pro项目下 src/main/java目录新建名为 ListFiles的类
(选中java文件夹->File->new->Java Class->在name选项中填入 ListFiles->Finish)
该实验的完整代码如下:
1 | import org.apache.hadoop.conf.Configuration; |
运行结果分析
使用和上节相同的方法运行代码。
输入根目录:/
运行结果如下:
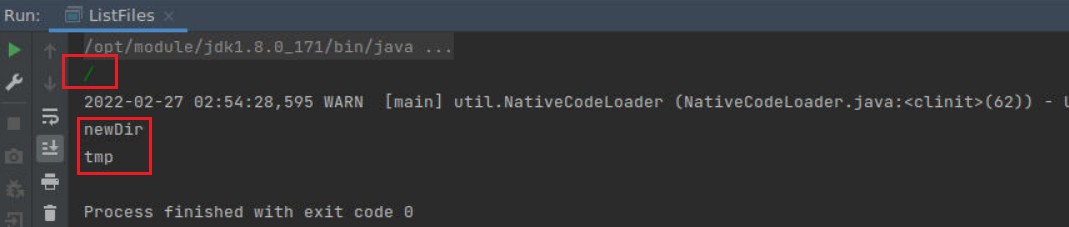
如图,程序成功列出了根目录下的所有文件。
删除目录
相关接口说明
删除文件可以使用FileSystem的delete接口,该接口的含义如下:
- 函数原型:
public abstract boolean delete(Path f,boolean recursive) throws IOException - 函数功能:删除文件或者目录。
- 参数说明:
f,要删除的文件或者目录的路径。recursive,是否需要递归删除。如果是删除目录的话,将该参数设置为true。否则,设置为false. - 返回值:如果成功删除,则返回
true。否则,返回false。 - 如果遇到IO故障,会抛出
IOException。
完整实验代码
将hdfs_pro项目下 src/main/java目录新建名为 DeleteDir的类
(选中java文件夹->File->new-> Java Class->在name选项中填入DeleteDir->Finish)
该实验的完整代码如下所示:
1 | import org.apache.hadoop.conf.Configuration; |
运行结果分析
使用和上节相同的方法运行代码。
输入目录名:newDir
运行结果如下:
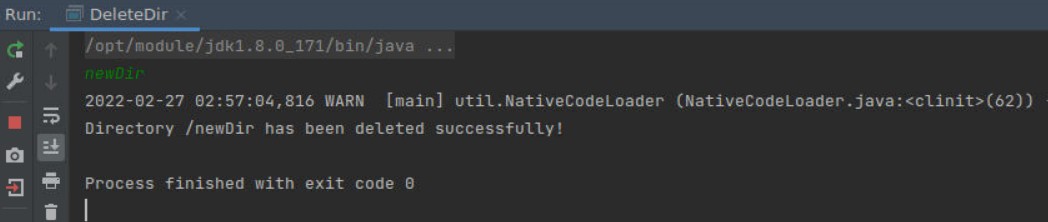
可以看到,之前创建的 newDir 目录被成功删除。
可以通过上一节中的ListFiles类进行验证。
文件的相关操作
创建文件
相关接口说明
使用FileSystem的create函数可以创建文件,根据参数的不同,create函数有以下几种重载类型:
1 | public FSDataOutputStream create(Path f) throws IOException |
上述接口中,各参数的含义分别如下:
f,要打开的文件名,默认会覆盖已经存在的文件。
overwrite,如果要创建的文件已经存在,是否覆盖。设置为true时,覆盖;为false时,不覆盖。
progress,用于汇报进度信息。
replication,设置文件块的副本数量。
bufferSize,所使用的缓冲区的大小。
blockSize,块大小。
permission,设置文件的权限。
flags,指定文件创建标志,文件创建标志包括:CREATE,APPEND,OVERWRITE ,SYNC_BLOCK,LAZY_PERSIST ,APPEND_NEWBLOCK等。
完整实验代码
将hdfs_pro项目下src/main/java目录新建名为CreateFile 的类
(选中java文件夹->File->new->Java Class->在name选项中填入CreateFile->Finish)
此次实验的完整代码如下所示:
1 | import org.apache.hadoop.conf.Configuration; |
运行结果分析
使用和上节相同的方法运行代码。
输入文件名:newfile.txt
运行结果如下:

在云桌面终端,输入命令验证
1 | root@cg:~/Desktop/workspace/hdfs_pro# hadoop fs -ls / |

如图所示,文件已经成功被创建。
文件存在性判断
相关接口说明
判断文件是否存在需要使用FileSystem的exists方法,该方法的详细含义如下:
方法名:exists
方法原型:public boolean exists(Path f) throws IOException
接口功能:检查某个路径所指的文件是否存在。
接口说明:参数f的含义为源路径。如果文件存在,返回值为true。如果IO故障会抛出IOException异常。
完整实验代码
将hdfs_pro项目下src/main/java目录新建名为FileExist 的类
(选中java文件夹->File->new->Java Class->在name选项中填入FileExist->Finish)
该实验的完整代码如下:
1 | import org.apache.hadoop.conf.Configuration; |
运行结果分析
点击Run运行代码。
输入文件名:newfile.txt
运行结果如下:
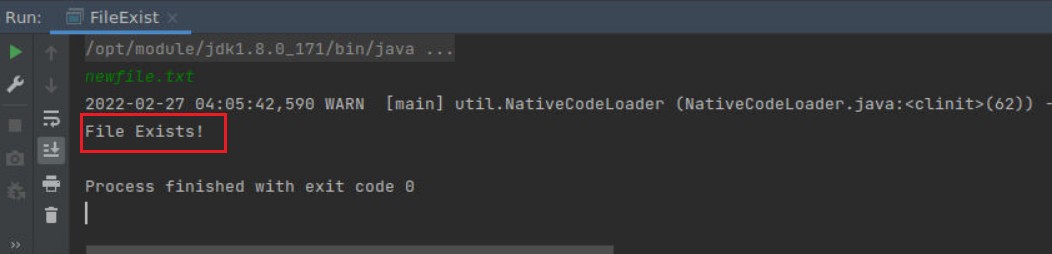
可以发现newfile.txt存在。
文件写
相关接口说明
HDFS不支持文件的随机写,写文件的方式有两种:1)文件不存在,创建文件之后,开始对文件的内容进行写入。2)文件存在,打开文件,在文件尾部追加写。
对于第一种方式,由于调用create方法后会返回FSDataOutputStream对象,使用该对象对文件进行写操作。第二种方式,使用FileSystem类的append接口,该接口也会返回FSDataOutputStream对象,同样使用该对象可对文件进行追加操作。
create方法在文件创建实验中已经进行了详细说明,这里对FSDataOutputStream的相关常用方法进行说明,FSDataOutputStream有三个常用的方法,分别为write,flush,close函数。write将数据写入到文件中,flush将数据缓存在内存中的数据更新到磁盘,close则关闭流对象。
FileSystem的append函数详细说明如下:
函数原型:public FSDataOutputStream append(Path f) throws IOException
函数功能:在一个已经存在的文件尾部追加数据。
函数参数:f,文件路径。
返回值:FSDataOutputStream对象。
异常:遇到IO故障时,抛出IOException异常。
完整实验代码
将hdfs_pro项目下src/main/java目录新建名为WriteFile 的类
(选中java文件夹->File->new->Java Class->在name选项中填入WriteFile->Finish)
该实验的完整代码如下所示:
1 | import org.apache.hadoop.conf.Configuration; |
该代码中,文件的写入分为两部分,第一部分使用create返回的FSDataOutputStream对象进行写入,第二部分使用append返回的FSDataOutputStream对象进行写入。
运行结果分析
点击Run运行代码。
输入文件名:newfile.txt
运行结果如下:
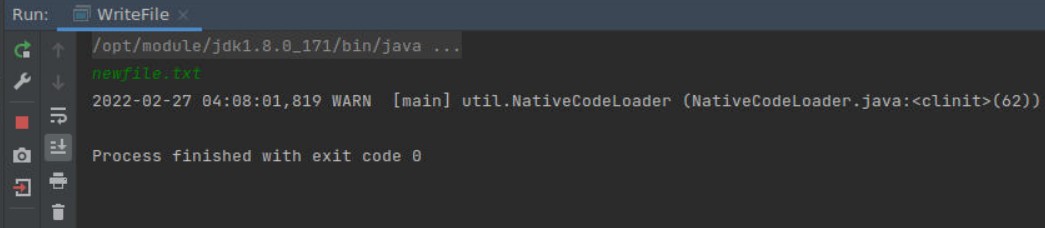
在云桌面终端,输入命令验证
1 | root@cg:~/Desktop/workspace/hdfs_pro# hadoop fs -cat /newfile.txt |

如图所示,文件成功写入。
文件读
相关接口说明
如果要读取HDFS上的文件,可以使用open方法。open方法会返回一个FSDataInputStream对象,使用该对象可对文件进行读操作。open函数详细说明如下:
函数原型:public FSDataInputStream open(Path f) throws IOException
函数功能:打开Path对象f指定的路径的文件。
参数说明:f,要打开的文件。
返回值:FSDataInputStream对象,利用FSDataInputStream对象可对文件进行读操作。
异常:遇到IO故障时,将抛出IOException。
open方法还有一个带有bufferSize参数的重载版本,该方法的原型为:
1 | public abstract FSDataInputStream open(Path f,int bufferSize) throws IOException |
其中,bufferSize的含义为读取过程中所使用的缓冲区的大小。
完整实验代码
将hdfs_pro项目下src/main/java目录新建名为ReadFile 的类
(选中java文件夹->File->new->Java Class->在name选项中填入ReadFile->Finish)
该实验的完整代码如下:
1 | import org.apache.hadoop.conf.Configuration; |
运行结果分析
点击Run运行代码。
输入文件名:newfile.txt
运行结果如下:
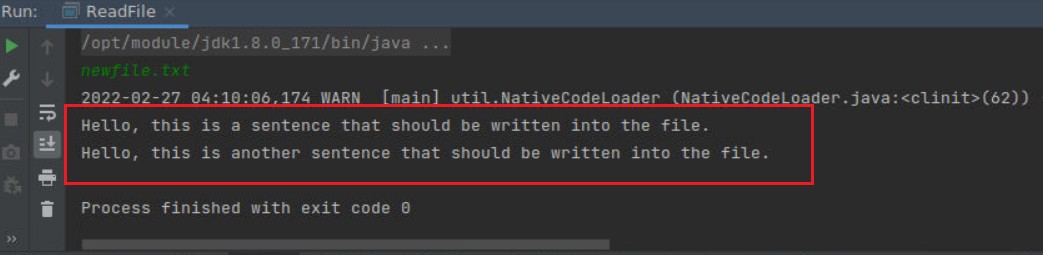
如图,文件中的内容成功被读取。
文件重命名
相关接口说明
文件重命名可以使用FileSystem的rename方法,该方法的详细说明如下:
函数原型:public abstract boolean rename(Path src,Path dst)throws IOException
函数功能:将路径src重命名为路径dst。
参数:src,将被重命名的路径。dst,重命名后的路径。
返回值:如果重命名成功,返回true;否则,返回false;
异常:如果遇到IO故障,抛出IOException异常。
完整实验代码
将hdfs_pro项目下src/main/java目录新建名为Rename 的类
(选中java文件夹->File->new->Java Class->在name选项中填入Rename->Finish)
该实验的完整代码如下:
1 | import org.apache.hadoop.conf.Configuration; |
运行结果分析
点击Run运行代码。
输入文件名与新的文件名:
1 | newfile.txt |
运行结果如下:
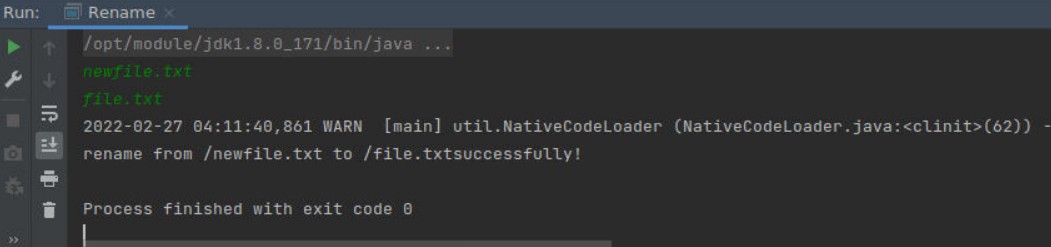
在云桌面终端,输入命令验证
1 | root@cg:~/Desktop/workspace/hdfs_pro# hadoop fs -ls / |

如图可以发现文件已经重命名。
文件删除
相关接口说明
删除文件可以使用FileSystem的delete接口,该接口的含义如下:
- 函数原型:
public abstract boolean delete(Path f,boolean recursive) throws IOException - 函数功能:删除文件或者目录。
- 参数说明:
f,要删除的文件或者目录的路径。recursive,是否需要递归删除。如果是删除目录的话,将该参数设置为true。否则,设置为false. - 返回值:如果成功删除,则返回
true。否则,返回false。 - 如果遇到IO故障,会抛出
IOException。
完整实验代码
将hdfs_pro项目下src/main/java目录新建名为DeleteFile 的类
(选中java文件夹->File->new->Java Class->在name选项中填入DeleteFile->Finish)
该实验的完整代码如下:
1 | import org.apache.hadoop.conf.Configuration; |
运行结果分析
点击Run运行代码。
输入文件名:file.txt
运行结果如下:
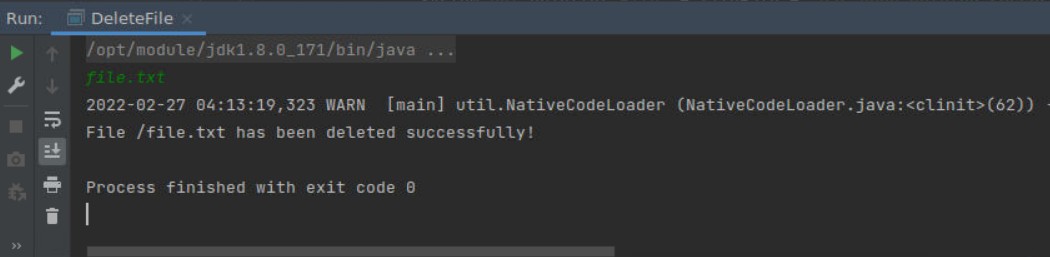
在云桌面终端,输入命令验证
1 | root@cg:~/Desktop/workspace/hdfs_pro# hadoop fs -ls / |

file.txt 已经被删除。
MapReduce编程
实验原理
MapReduce组成原理
最简单的MapReduce应用程序至少包含 3 个部分:一个 Map 函数、一个 Reduce 函数和一个 main 函数。在运行一个mapreduce计算任务时候,任务过程被分为两个阶段:map阶段和reduce阶段,每个阶段都是用键值对(key/value)作为输入(input)和输出(output)。main 函数将作业控制和文件输入/输出结合起来。
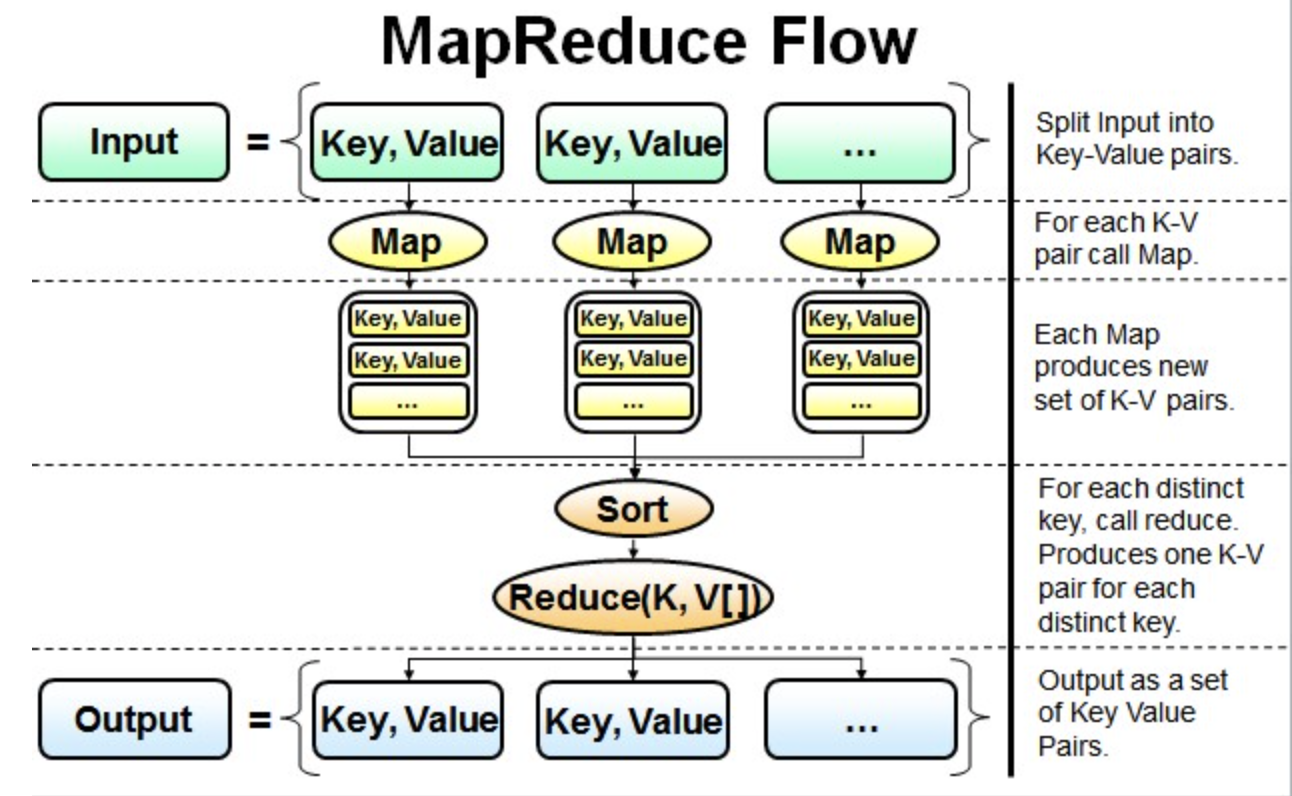
并行读取文本中的内容,然后进行MapReduce操作。
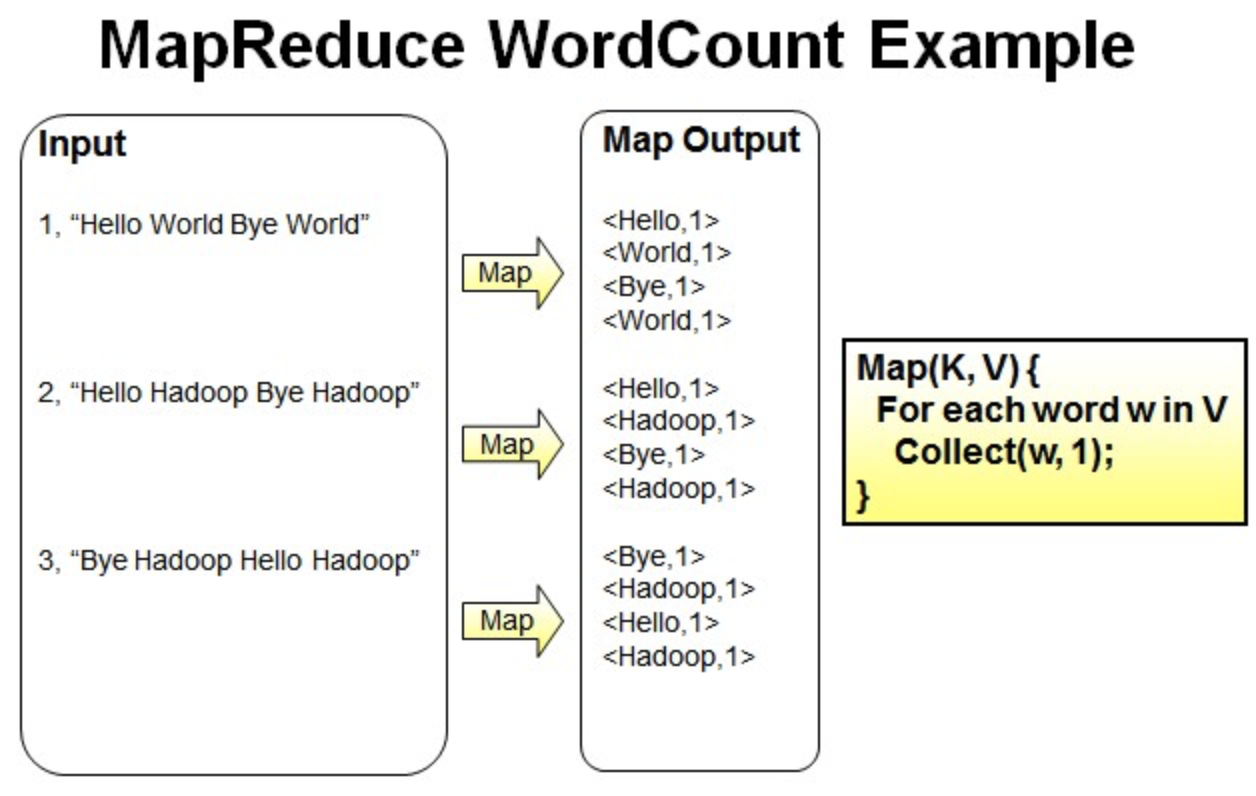
Map过程:并行读取文本,对读取的单词进行map操作,每个词都以<key,value>形式生成。
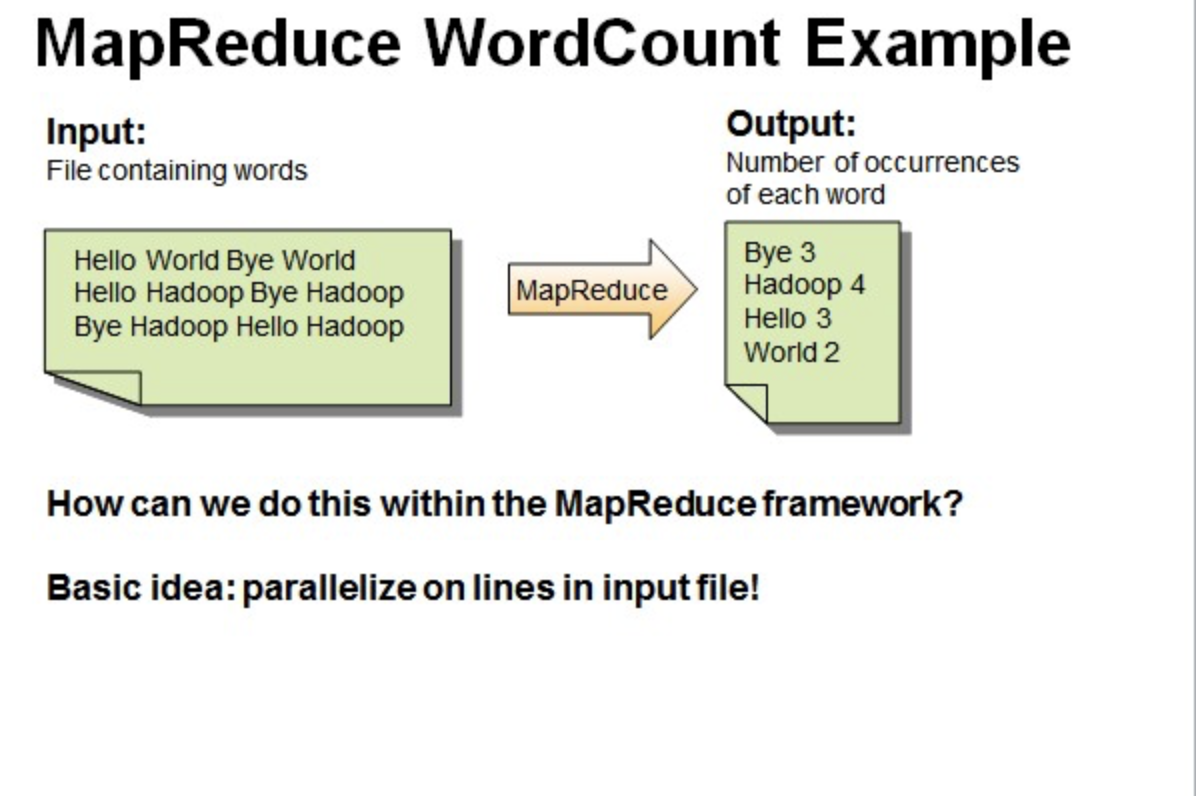
一个有三行文本的文件进行MapReduce操作。
读取第一行Hello World Bye World ,分割单词形成Map。
<Hello,1> <World,1> <Bye,1> <World,1>
读取第二行Hello Hadoop Bye Hadoop,分割单词形成Map。
<Hello,1> <Hadoop,1> <Bye,1> <Hadoop,1>
读取第三行Bye Hadoop Hello Hadoop,分割单词形成Map。
<Bye,1> <Hadoop,1> <Hello,1> <Hadoop,1>
Reduce操作是对map的结果进行排序,合并,最后得出词频。
经过进一步处理(combiner),将形成的Map根据相同的key组合成value数组。
<Bye,1,1,1> <Hadoop,1,1,1,1> <Hello,1,1,1> <World,1,1>
循环执行Reduce(K,V[]),分别统计每个单词出现的次数。
<Bye,3> <Hadoop,4> <Hello,3> <World,2>
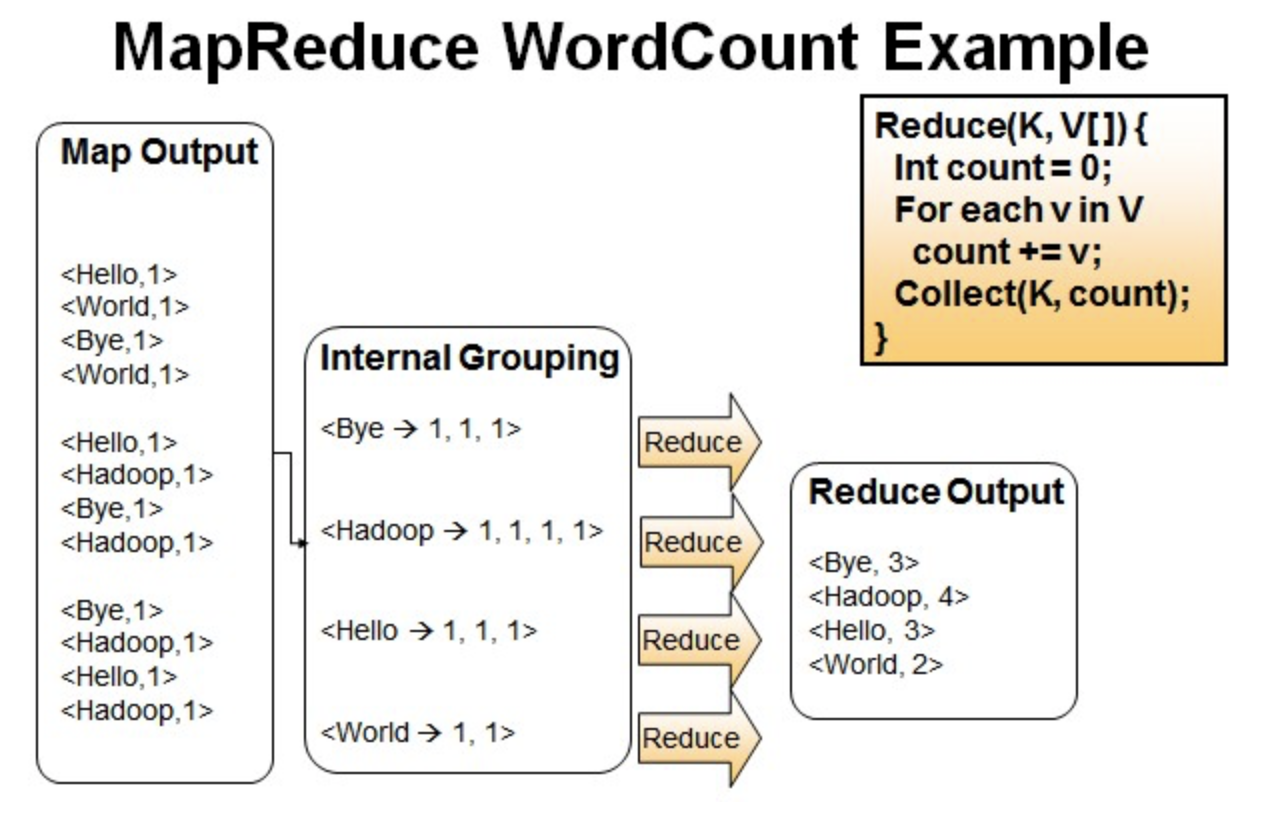
WrodCount处理过程
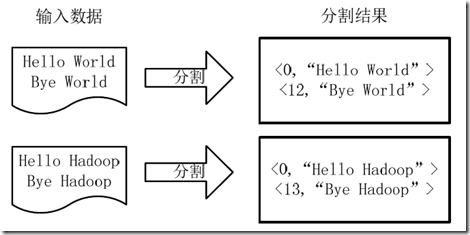
1.将文件拆分成splits,由于测试用的文件较小,所以每个文件为一个split,并将文件按行分割形成<key,value>对,如下图所示。这一步由MapReduce框架自动完成,其中偏移量(即key值)包括了回车所占的字符数(Windows和Linux环境会不同)。
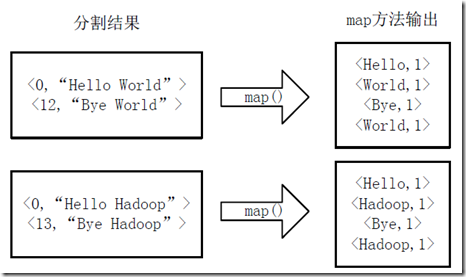
2.将分割好的<key,value>对交给用户定义的map方法进行处理,生成新的<key,value>对,如下图所示。
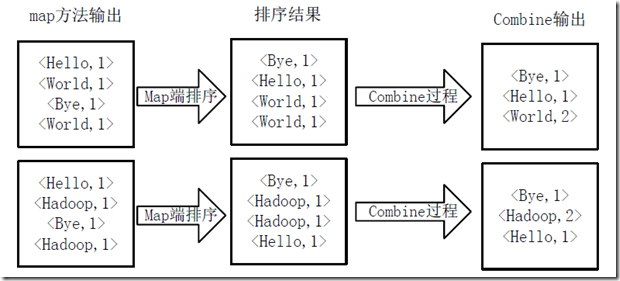
3.得到map方法输出的<key,value>对后,Mapper会将它们按照key值进行排序,并执行Combine过程,将key至相同value值累加,得到Mapper的最终输出结果,如下图所示。
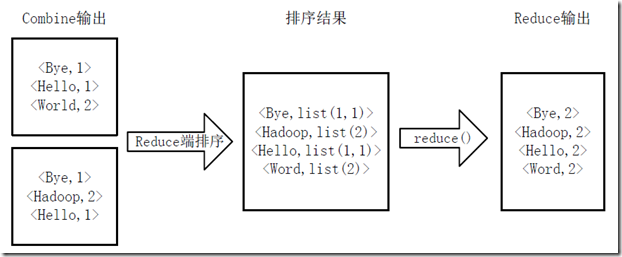
4.Reducer先对从Mapper接收的数据进行排序,再交由用户自定义的reduce方法进行处理,得到新的<key,value>对,并作为WordCount的输出结果,如下图所示。
准备
在master环境启动Hadoop服务,操作见上述
创建工作目录
本实验的工作目录为~/Desktop/workspace/mapreduce,使用以下命令创建和初始化工作目录:
1 | root@cg:~/Desktop# mkdir -p ~/Desktop/workspace/mapreduce |

- 标题: 大数据处理与实践(1)——Hadoop
- 作者: 狮子阿儒
- 创建于 : 2024-03-07 21:19:01
- 更新于 : 2024-04-09 21:45:50
- 链接: https://c200108.github.io/blog/2024/03/07/大数据处理与实践(1)——Hadoop/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。